0. 요약
- Multi-modality 데이터 퓨전을 통한 Semantic Segmentation 연구가 이루어져 왔다
- 하지만, Fusion 기반 접근은 Point-Pixel 간의 정확한 매핑이 (학습과 추론 단계에서) 이뤄져야 한다
- 제안하는 2D Pass 방법은 2D 이미지를 충분히 활용하되, 엄검한 데이터 쌍의 제약이 없어서 세그멘테이션을 수행할 수 있게 해준다.
- 2D Pass는 Auxiliary Modal Fusion(보조 모달 융합)과 Multi-Scale Fusion-to-Single Knowledge Distillation(MSFSKD, 다중 스케일 융합-단일 지식 증류)를 활용하여 풍부한 의미론적 및 구조적 정보를 획득한 다음 Pure 3D 네트워크(?)로 Distilled(?) 된다
- SemanticKITTI에서 Single/Multi Scan에서 1st 달성
1. 서문
- Semantic Segmentation 관련 논문 들
- Randla-net: Ecient semantic segmentation of large-scale point clouds, 2020
- Sparse single sweep lidar point cloud segmentation via learning contextual shape priors from scene completion, 2021
- 3d semantic segmentation with submanifold sparse convolutional networks, CVPR2018
- Squeezesegv3: Spatially-adaptive convolution for ecient point-cloud segmentation
- Cylindrical and asymmetrical 3d, CVPR2021
- SPVNAS, Searching ecient 3d architectures with sparse point-voxel convolution, ECCV2020
- Camera-Lidar 퓨전 연구
- Perception-aware multisensor fusion for 3d lidar semantic segmentation, ICCV2021
- Rgb and lidar fusion based 3d semantic segmentation for autonomous driving. ITSC2019
- Pointpainting: Sequential fusion for 3d object detection, ICCV2020
- 초기 위와 같은 퓨전 연구는 3D Points를 2D Pixels로 센서 켈리브레이션 정보를 이용해 프로젝션하는 방식을 취했다. Point-to-Pixel 매핑 기반으로 모델은 이미지 특징 정보를 Points에 결합하였고, 더 나은 Semantic 점수를 얻었다.
- 위와 같은 성능 향상에도 불구하고, Fusion 기반 방법은 한계가 있었는데
1) 두 센서간 FOV 차이로 인해, Point-to-Pixel 매핑은 이미지 영역 밖으로는 수행되지 못했다(아래 그림 참조)
2) 퓨전 기반 방법은 Image와 Point를 동시에 (Multitask or Cascase 방법으로) 처리하기 때문에 연산이 많이 들어 실시간 처리에 어려움이 있었다.
- 본 논문에서는 센서가 Scenes에서 움직이는 것을 고려하면, 라이다 360 중에 이미지와 겹치지 않는 부분은(아래 그림의 회색 부분) 다른 타임스탬프의 이미지로 덮일 수 있다는 것에 착안했다. 또한, 영상의 조밀하고 구조적인 정보는 포인트 클라우드 영역의 보이거나 보이지 않는 지점에 유용한 정규화를 제공한다(?) 이러한 관찰을 바창으로 "모델에 독립적인" 학습 전략인 2D Prior Assisted Semantic Segmentation(2D PASS)를 제안한다.

- 실전에서 2DPASS는 비중첩 영역(Point-Pixel 만나지 않는 부분 회색 부분)의 포인크 클라우드는 모델 훈련을 위한 입력으로 사용한다. 반면, Point-to-Pixel 매칭이 잘 정렬된 영역에 대해서는 Auxiliary Multi-Modal Fusion(보조 멀티 모달 융합)을 채택해서 각 스케일의 이미지 및 포인트 특징을 융합(Aggregate) 한 다음 3D 예측을 융합 예측과 정렬 한다.
--> 여기서 문제가 발생할 수 있을 듯, 현재 MMS 데이터는 매칭이 잘 정렬되지 않은 부분이 존재하기 때문에
- Modal의 특정 정보를 오염(?) 시키기 위운 이전 Cross-modal 정렬방식 과 달리
(xmuda: Cross-modal unsupervised domain adaptation for 3d semantic segmentation, CVPR2020)
본 논문에서는 추가 지식을 3D 모델에 전달하고, 모달 특화된 능력을 유지하기 위한 Multi-Scale Fusion-to-Single Knowledge Distillation(MSFSKD, 다중 스케일 융합-단일 지식 증류) 을 디자인 하였다
- 기존의 퓨전 방법에 비해 우리의 방법은 다음과 같은 특징이 있다
1) 일반성: 본 논문의 방법은 최소한의 수정으로 3D 세그멘테이션 모델과 통합될 수 있다.
2) 유연성: 퓨전 모듈은 학습에서만 사용되고, 학습 후에는 성능 향상된 3D 모델은 이미지 입력 없이 배포될 수 있다.
3) 효율성: 작은 영역만 (이미지-라이다가) 겹치더라도, 즉 overlapped multi-modality data 가 조금만 존재하더라도, 본 논문의 방법은 성능을 향상시킬 수 있다.
- 결과적으로 본 논문은 Sparse Convolutions으로 구현된 베이스 라인을 가지고 간단하게 2D Pass를 실험할 수 있었다.
(베이스 라인 논문: 3d semantic segmentation with sub manifold sparse convolutional networks, CVPR2018)
- 주요 기여)
: 2D 사전 지원(Priors Assisted) Semantic Segmentation (2DPASS) : 3D LiDAR semantic segmentation with 2D priors from cameras. 2DPASS는 의미론적 분할을 위해 다중 모드 지식(multi-modal knowledge)을 단일 포인트 클라우드 모드로 증류(?, distill)하는 최초의 방법입니다.
: Multi-Scale Fusion-to-Single Knowledge Distillation(MSFSKD, 다중 스케일 융합-단일 지식 증류) 방법을 이용해 SemanticKITTI랑 NuScenes에서 1등을 찍었다.
2. Related Work
2-1. 단일 센서 모델
2-1-1) 포인트 기반 방식은 포인트 별 MLP(Multi-Layer Perceptron)을 적용하여 순열 불변 집합 함수를 근사화 한다. 하지만, 포인트 기반 방법은 sampling과 grouping에 시간 소모가 너무 큰 문제가 있다.
: point-wise MLP
- Pointnet++: Deep hierarchical feature learning on point sets in a metric space, NIPS2017
- Dynamic graph cnn for learning on point clouds, ACM2019
: Adaptive weight
- Pointconv: Deep convolutional networks on 3d point clouds
- Relation-shape convolutional neural net work for point cloud analysis.
: pseudo grid
- Kpconv: Flexible and deformable convolution for point clouds, ICCV2019
- Pointwise convolutional neural networks, CVPR2018
: Non-local operator
- Pointasnl: Robust point clouds processing using nonlocal neural networks with adaptive sampling
- Point transformer
2-1-2) 프로젝션 기반 방식
- 이미지로 변환하였기 때문에 CNN을 적용할 수 있는 장점이 있다. 하지만, 정보의 손실이 존재한다. 또한, 최근에 성능의 보틀넥이 존재한다.
: 평면 프로젝션
- Deep projective 3d semantic segmentation.
- Unstructured point cloud semantic labeling using deep segmentation networks
- Tangent convolutions for dense prediction in 3d, CVPR2018
: 구(Spherical) 프로젝션
- Squeezeseg: Convolutional neural nets with recurrent crf for real-time road-object segmentation from 3d lidar point cloud.
- Squeezesegv2: Improved model structure and unsupervised domain adaptation for road-object segmentation from
a lidar point cloud, ICRA2019
2-1-3) 복셀 기반 방식
- 모든 점을 3D 복셀 그리드로 변환하는 기존 복셀 기반 방법(3DCNN) 대비, SparseConv는 비어 있지 않는 복셀만 해시 테이블에 저장하고, 비어 있지 않는 복셀에 대해서만 컨볼루션 연산을 수행한다.
- Cyclinder3D는 오리지널 복셀 그리드을 비대칭 원통 형태로 디자인 하였고,
- AF2-S3Net은 다른 커널 사이즈를 이용한 다수 브랜치를 적용하여 Multi-Scale 특징을 Attention Machanism을 이용해 모았다.
2-1-4) 다수 표현 퓨전(Multi Representation Fusion)
- [SPVNAS, Searching ecient 3d architectures with sparse point-voxel convolution, ECCV2020] 논문은 각각의 Sparse Conv 블락에 Point-Wise MLP를 결합하여 Point-Voxel 표현을 학습하였다. 그리고 NAS를 적용하였다.
(SpaseConv 블락은 해시를 이용해 효율적으로 복셀을 만드는 방법인데, 여기에 포인트 단위로 적용하는 MLP를 결합하였다는 뜻)
- [Rpvnet: A deep and efficient range-point-voxel fusion network for lidar point cloud segmentation, ICCV2021] 논문은 range-point-voxel 퓨전 네트워크를 제안하여 표현으로 부터 오는 정보를 활용하였다.
- 그럼에도 불구하고 다음의 방법들은 Sparse하고 (이미지에는 있지만 라이다에는 없는)텍스쳐가 없는 라이다 포인트 만을 입력으로 사용하였다.
2.2 다중 센서 모델
- [RGBAL, Rgb and lidar fusion based 3d semantic segmentation for autonomous driving, ITSC2019] 논문은 RGB 이미지를 polar-grid 매핑하여 early & mid-level 퓨전을 시도하였다.
- [Pointpainting: Sequential fusion for 3d object detection, ICCV2020] 는 이미지의 분할 logits을 이용하여 Bird-Eye 혹은 Spherical 투영을 통해 이미지를 라이다 공간에 투영하였다.
- 위의 방법들은 멀티 센서 입력을 학습/추론시에 필요로 한다. 이는 계산량이 많이 필요하고, 실생활에서 유용하지 않다(computation-intensive & unavailable in practical application)

2DPASS는 이미지에서 작은 패치를 자르고, 잘려진 이미지와 라이다는 2D/3D 인코더에 독립적으로 들어가서 multi-scale feature를 생성한다. 다음, 2D 지식은 multi-scale-fusion-to-single knowledge distillation을 통해 전파된다. 특징맵은 모달-디코더를 사용하여 최종 Score Semantic 점수를 생성하는데 사용된다.
2.3 크로스 모달 지식 전이(Cross-modal Knowledge Transfer)
2D 사전 지식을 잘 설계된 퓨전 모듈에 전파하여, 모달에 특화된 지식을 처리한다.
3. 방법
- 실외 포인트 클라우드의 Sparsity, Varying density, lack of texture를 처리하기 위해 Fusion--to-Single 지식 전이를 통해 2D 이미지의 정규화 및 사전 지식을 도입하였다.
- (2D 이미지에 대응되는 3D 라이다 패치 인건가???)
- 카메라 이미지가 꽤나 크기 때문에(1242 x 512) Multi-Modal 파이프라인에 전달하기는 꽤나 어렵다. 따라서, 스몰 패치를 샘플링하여 학습 속도를 가속화 하였다.
- 2D 이미지랑 3D 라이다가 독립적으로 인코더에 통과되고, MSFSKD이 3D 네트워크를 강화하기 위해 수행된다.
(이미지의 강점인 Texture 및 색상 인식을 통해 2D 사전지식을 3D 네트워크에 전파한다)
- 추론하는 동안 2D 관련 Branch를 버릴수 있다(?), 따라서 융합기반의 기존 방식 대비 계산 부담이 덜하다.
3.2 멀티 모달 특화된 아키텍쳐
<인코더>
- 2D 인코더는 ResNet34를 3D 인코더는 SparseConv를 적용하였다.
- 계층적 인코더를 SPVCNN로 설계 하였다(?), 각 스케일에서 ResNet 보틀넥을 적용하였다(?) Relu를 Leaky Relu로 대체
- $F_l^{2D}, F_l^{3D} $
<디코더>
- 두개의 모달에 특화된 예측 디코더가 독립적으로 각각 적용되어 본래 크기로 복원한다. 2D 네트워크에는 FCN 디코더를 적용하였다.
- $D_l^{2D}$ 특징맵은 (L - l + 1)번째 인코더를 업셈플링하여 얻어진다. 업셈플링 피처맵은 요소합으로 합병된다.
- 마지막으로 2D 네트워크의 세멘틱 세그멘테이션은 선형 분류기를 통과하여 얻어진다(?)
3.3 포인트-픽셀 대응

(a)
- 포인트 클라우드는 이미지에 프로젝션되어 Point-To-Pixel 매핑을 진행한다.
- 이후 2D 피처맵을 P2P 매핑에 따라 Point-Wise 2D 피처맵에 전달한다.
(b)
- Point-T-Voxel 매핑은 쉽게 얻어지며, Voxel 특징은 포인트 클라우드 상에서 보간된다.
NuScenes에서는 라이다와 카메라가 다른 Frequency로 동작하기 때문에, tl 타임스탬프에서 라이다 프레임을 tc 타임스탬프의 카메라 프레임으로 변환해야 한다.

Point-to-Pixel 매핑
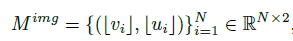
Point-to-Voxel 매핑

Filter the Points by discarding points outside of the image FOV

2D GT는 3차원 포인트 클라우드를 2D 이미지에 프로젝션 시킨 것이다.
ㄴSPVCNN
#SPVCNN
class get_model(LightningBaseModel):
def __init__(self, config):
super(get_model, self).__init__(config)
self.save_hyperparameters()
self.input_dims = config['model_params']['input_dims'] # 4
self.hiden_size = config['model_params']['hiden_size'] # 64
self.num_classes = config['model_params']['num_classes'] # 20
self.scale_list = config['model_params']['scale_list'] # [2, 4, 8, 16]
self.num_scales = len(self.scale_list) # 4
min_volume_space = config['dataset_params']['min_volume_space'] # [-50, -50, 4]
max_volume_space = config['dataset_params']['max_volume_space'] # [50, 50, 2]
self.coors_range_xyz = [[min_volume_space[0], max_volume_space[0]],
[min_volume_space[1], max_volume_space[1]],
[min_volume_space[2], max_volume_space[2]]]
self.spatial_shape = np.array(config['model_params']['spatial_shape']) #[1000, 1000, 60]
self.strides = [int(scale / self.scale_list[0]) for scale in self.scale_list] #[1, 2, 4, 8]
# voxelization
self.voxelizer = voxelization(
coors_range_xyz = self.coors_range_xyz,
spatial_shape = self.spatial_shape,
scale_list = self.scale_list
)
# input processing
self.voxel_3d_generator = voxel_3d_generator(
in_channels = self.input_dims,
out_channels = self.hiden_size,
coors_range_xyz = self.coors_range_xyz,
spatial_shape = self.spatial_shape
)
# encoder layers
self.spv_enc = nn.ModuleList()
for i in range(self.num_scales):
self.spv_enc.append(
SPVBlock(in_channels = self.hiden_size,
out_channels = self.hiden_size,
indice_key = 'spv_' + str(i),
scale = self.scale_list[i],
last_scale = self.scale_list[i-1] if i > 0 else 1,
spatial_shape = np.int32(self.spatial_shape // self.strides[i])[::-1].tolist())
)
# decoder layer
self.classifier = nn.Sequential(
nn.Linear(self.hiden_size * self.num_scales, 128),
nn.ReLU(True),
nn.Linear(128, self.num_classes),
)
#loss
self.criterion = criterion(config)
def forward(self, data_dict):
with torch.no_grad():
data_dict = self.voxelizer(data_dict)
data_dict = self.voxel_3d_generator(data_dict)
enc_feats = []
for i in range(self.num_scales):
enc_feats.apped(self.spv_enc[i](data_dict))
output = torch.cat(enc_feats, dim = 1)
data_dict['logits'] = self.classifier(output)
data_dict['loss'] = 0.
data_dict = self.criterion(data_dict)
return data_dict


