▶Abstract
- 딥러닝은 컴퓨터 비전 분야에서 비약적인 발전을 이뤘지만, 시각적 측위 능력을 개선하는 데는 아직 부족하다
- 주요 장애물 중 하나는 기존 CNN(Convolutional Neural Network) 기반 포즈 회귀 방법이 기존에 보지 못했던 장소를 일반화 하지 못한다는 것이다.
- 최근에 도입된 CMRNet은 LiDAR 맵에서 독립적인 단안 측위(independent monocular localization)를 가능하게 하여 이러한 제약 사항을 효과적으로 해결하였다.
- CMRNet++은 더욱 강건하고, 카메라 파라미터에도 독립적인 네트워크이다.
- 본 논문에서는 딥 러닝을 기하학적 기술과 결합하고, 메트릭 추론을 학습 프로세스 밖으로 이동시켰다.
- 이러한 방법 덕분에, 네트워크 가중치는 특정 카메라에 종속되지 않게 된다.
- KITTI, Argoverse, Lyft5 데이터로 실험을 하였다.
- 더욱 중요한 것은, 처음으로 카메라 파라미터에 독립적이면서, 재학습/미세 조정 없이 정확한 측위가 가능한 딥러닝 접근 방식을 시현했다는 것이다.
▶서론
- PoseNet, VLocNet++, Scene Coordinate Regression forest 등은 실내에서 잘 동작하지만, 실외에서는 성능이 부실하다.
- HD Map은 포인트 클라우드로 재구성한 도로 장면 정보를 활용한다.
- 측위는 일반적으로 카메라 Scene의 3차원 형상을 재구성한 다음 이 재구성을 지도와 일치시키거나, 이미지 평면에서 일치(?) 시킴으로서 수행할 수 있다.
- CMRNet은 카메라-Lidar 포즈 켈리브레이션(카메라 파라미터 추정) 방법이고, CMRNet++은 카메라-라이다 정합 방법이다.
- CMRNet은 맵에 독립이고, CMRNet++은 더 나아가 카메라 파라미터에 독립이다.
- 포즈 회귀하는 PoseNet, VLocNet++ 과 달리, CMRNet은 맵과 이미지를 매칭시키는 것을 학습한다.
- 그러나, CMRNet 출력은 (초기 포즈 대비) 6Dof 강체 변환 메트릭이므로, 네트워크 가중치는 카메라 내부 파라미터와 연결된다(종속된다).
- 본 논문은 측위를 (1) 픽셀-3D 포인트 매칭 (2) 포즈 회귀 이렇게 두 단계로 분리하였다.
▶기술적 접근
(1) 픽셀-3D 포인트 매칭
- GNSS에서 얻은 대략적인 포즈 장소인 $H_init$ 에서 맵 상의 라이다를 이미지에 투영하여 합성 Depth Image를 생성한다. 투영시에는 카메라 내부 행렬을 이용한다.
- 포인트 클라우드 가려짐을 처리하기 위해 z-버퍼 기술과 가려짐 추정 필터를 사용한다.
- 모든 3D 포인트에 대해서, RGB 픽셀을 추정한다.
- CMRNet++ 아키텍쳐는 두개의 연속된 RGB 이미지에서 Optical Flow를 추정하는 PWC-Net을 기반으로 하지만, PWC-Net과는 다르게, 두개의 피처 피라이드 Extractors 들 간의 가중치는 공유하지 않는다.
- CMRNet++의 출력 결과는 입력 대비 1/4 해상도 이며 (라이다-이미지 투영), (같은 WorldPoint를 가리키는 RGB 간의 위상차)를 나타낸다.
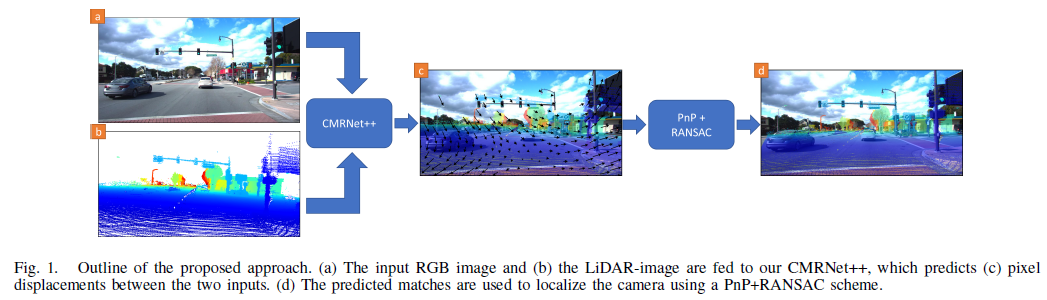
(1-1) 입력의 준비
H_init 참조 프레임에서 Eq1 식을 이용해서 지도 지점의 좌표를 계산한다. 지도 지점의 좌표에서 카메라 행렬 를 이용해서 픽셀 위치를 계산한다.

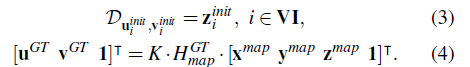
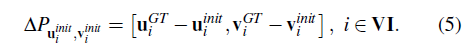
배열 VI에서 유효한 포인트의 인덱스를 추적한다. 이는 투영이 이미지 평면의 뒤 또는 외부에 있거나, 가려짐 추정 필터에 의해서 Occluded로 표현된 점을 제외하고 수행된다. 투영된 점의 픽셀 위치를 계산한 뒤, GT 위상 $\vartriangle{P}$를 계산한다.
3D 포인트와 연관되지 않는 이미지 평면상의 픽셀은 깊이와 위상차가 0 이다(무슨말 인지?)
$$ D_{u, v} = 0 $$
$$ \vartriangle{P}_{u, v} = [0, 0] $$
(1-2) 로스
D_smooth 는 GT가 없는 픽셀(대응되는 3D 포인트가 없는 픽셀) 에 대해서는 이웃 픽셀과 유사해지도록 학습한다(?)
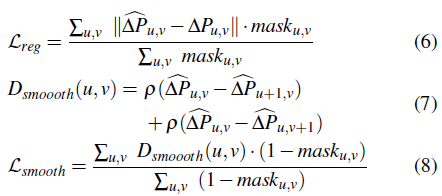
(2) 측위
- 좌표점을 알고 있는 3D 점 P와 투영이미지 D가 주어질 때, 매칭 점 p를 CNN이 예측한다.
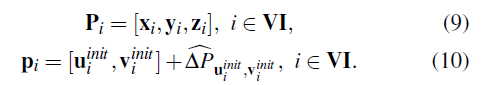
- 카메라 포즈를 추정하는 것은 PnP 문제로 알려져 있다.
(3) 반복적 정제
- RGB 및 LiDAR 이미지를 가장 높은 오류 범위로 훈련된 네트워크에 공급하고, 예측된 포즈에 지도를 투영하여 새로운 라이다-이미지를 생성한다. (포즈에 지도를 투영한다??)
- 결과는 낮은 오류 범위로 훈련된 CMRNet++의 두 번째 인스턴스에 공급된다. 해당 프로세스는 반복하여, 측위 정확도를 반복적으로 개선할 수 있다(?)
(4) 학습
- 300 epoch, P100, Adam, lr 1.5 * 10^(-4), wd 5*10^(-6), 20/40 epoch 마다 lr를 반으로 줄였다.
▶실험 결과
- KITTI와 Argoverse로 학습을 하였고, 두 데이터 카메라 해상도가 다르기 때문에 Argoverse 이미지 해상도를 줄인 다음에 KITTI와 Argoverse 각각을 랜덤 Crop 하였다(960 x 320)
- Lidar-이미지 D와 GT 위상 $\vartriangle{P}$ 를 본래 해상도에서 생성한 다음에, 다운 샘플링과 Crop을 진행하였다.
초기 포즈 샘플링과 데이터 증강
초기 포즈 H_init를 실험하기 위해서 H_GT에 랜덤 노이즈를 추가하였다. T -> [+-2m], R -> [+-10˚]
두번째 세번째 이터레이션에서는 T -> [+-`m], R -> [+-1˚] , T -> [+-0.6m], R -> [+-1˚] 로 변경하였다. (왜???)
이는 예측된 일치 항목의 절반 이상이 잘못되어 PnP+RANSAC가 잘못된 솔루션을 추정하는 첫 번째 반복에서 특히 발생할 수 있습니다.
그 원인은 지면의 픽셀 일치에 있다고 생각합니다. 도로 표면의 균일한 모양으로 인해 특정 3D 지점과 일치하는 정확한 픽셀을 인식하는 것이 거의 불가능합니다.
▶총평
- 본 논문 방식은 단안 카메라 영상 측위가 목적이다. 본 방법을 위해서 카메라와 라이다가 켈리브레이션된 GT 정보를 필요로 한다.
- 초기 이동 값(H_init)를 정하고, 이미지에 투영 시킨 다음에 GT 픽셀 위치와 비교한다. 따라서, H_init와 K를 바로 잡아 나가는 식으로 학습한다.
- 학습 단계에서 K를 추정하는 것 까지 포함하였기 때문에 카메라 파라미터에 독립적인 모델이라고 표현한 것 같다.
- 상세하게 본 논문의 방법을 이해한 것은 아니기 때문에, 코드를 봐야 구체적으로 파악할 수 있을 것 같다.
<질문>
- 본 방법은 카메라-이미지가 켈리브레이션이 완전한 상황에서 데이터를 준비하는데, 처음부터 카메라와 라이다가 켈리브레이션 되지 않은 상황에서는 본 네트워크를 적용하기 힘들진 않을지?
즉, Ground truth pixel displacement of the LiDAR-image w.r.t. RGB image
'논문 리뷰(Paper Review)' 카테고리의 다른 글
| CVPR2023 참관 후기 (0) | 2023.06.24 |
|---|---|
| Unsupervised Domain Adaptation by Backpropagation(in ICML'15) (0) | 2023.05.11 |
| 2DPASS: 2D Priors Assisted SemanticSegmentation on LiDAR Point Clouds (0) | 2022.10.21 |
| HDMapGen: A Hierarchical Graph Generative Model of High Definition Maps, CVPR2021 (0) | 2022.07.19 |
| Cylindrical and Asymmetrical 3D Convolution Networksfor LiDAR Segmentation (0) | 2022.06.23 |



