개요

MultiView를 이용한 3D 논문이 가장 많았고 대부분 Nerf를 응용한 주제가 상당수를 차지했고,
라이다와 영상을 활용하거나 라이다 데이터 셋을 이용한 3D Representation Learning 이 존재하였다.
Image 합성, 비디오 생성 및 Human pose를 예측하는 논문도 많이 볼 수 있었다.
흥미로운 부분은 Vision과 Language를 결합한 Multi-Modal 주제의 논문도 OpenAI의 Clip 이후로 등장하는 추세였고, 자율 주행 그자체를 주제로 다룬 논문은 그리 많지 않았다.
2359개의 논문이 Accept 되었고, 25.8% Acceptance rate이다.

살펴본 논문
(화-오전)
112. ULIP: Learning a Unified Representation of Language, Images, and Point Clouds for 3D Understanding, Le Xue, Mingfei Gao, Chen Xing, Roberto Mart-Mart, Jiajun Wu, Caiming Xiong, Ran Xu, Juan Carlos Niebles, Silvio Savarese
114. FlatFormer: Flattened Window Attention for Efficient PointCloud Transformer, Zhijian Liu, Xinyu Yang, Haotian Tang, ShangYang, Song Han
서론
- 트랜스포머는 높은 성능에도 불구하고, (라이다 특징 추출에 주로 쓰이는) Sparse 컨볼루션 대비 Latency가 3배 가량 느리다. 이는 Sparse 컨볼루션이 포인트 클라우드 데이터셋 특징에 맞춰 Sparse하고 Irregular한 속성에 맞춰 설계된 것 대비 트랜스포머 구조는 Dense하고 Regular한 데이터셋을 타겟으로 설계 되었기 때문
관련 연구
- Global PCT: 각 포인트를 토큰(Token)으로 간주하여 전체 포인트에 대해 Multi-Head-Self-Attention(MHSA) 적용. 당연히 OutDoorScene에서는 적용이 불가능하고, Sparse Conv 대비 동일환경에서 66배 가량 느리다
- Local PCT: 각 포인트 전체에 대해서 MHSA를 적용하는 것이 아닌, 포인트 이웃에 대해 적용하는 방법. 하지만, 이웃을 찾는(Neighbor Preparation) 과정에서 여전히 연산이 많이 든다.
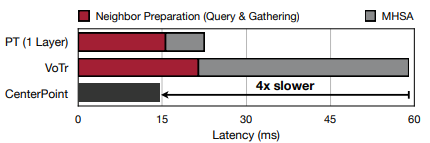
- WindowPCT: SwinTransformer의 성능 향상에 힘입어, 포인트 클라우드 BEV에 윈도우 사이드를 나눠 MHSA를 적용한 방법이 제시 되었지만, 포인트 클라우드 프로젝션 이미지도 포인트 갯수가 균일하지 않은 문제와 패딩 이슈가 발생
※ Swin Transformer: 각기 다른 도메인에서 트랜스포머 연산을 적용할 시에 스케일이 서로 다른 문제를 해결하기 위해 계층적(Hierarchical) 트랜스 포머와 Shifted Window를 적용한 방법

개발 요약
- 창 기반 정렬(window-based sorting)을 사용하여 포인트 클라우드를 평면화하고, 포인트를 동일한 모양의 창이 아닌 동일한 크기의 그룹으로 분할합니다.
- 이후 그룹 별로 self-attention을 적용하여 특징 추출을 수행하고, 정렬 축을 여러 방향에서 수행하고 창을 이동하여 그룹 간에 특징을 교환하였다.

성능
- Waymo OpenDataset에서 SST 대비 4.6배, CenterPoint 대비 1.4배 속도 증가


총평
- 본 논문은 SwinTransformer에서 Window 사이즈 마다 다른 포인트 갯수를 가지는 문제를 균일하게 맞춰 준 것을 주요 아이디어로 제시한 것 같다.

(화-오후)
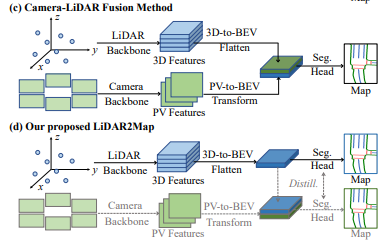
100. LiDAR2Map: In Defense of LiDAR-Based Semantic Map Construction Using Online Camera Distillation, Song Wang, Wentong Li, Wenyu Liu, Xiaolu Liu, Jianke Zhu
주요 특징
- BEV Feature Pyramid Decoder
- 영상에서 추출한 특징을 Lidar 기반 Feature에 distillation 하기 위한 Camera-to-LiDAR distillation
(Distillation은 Feature-Level, Logit-Level로 나뉜다)
- Position Guided Feature Fusion Module(PGF2M), Feature-Level Distillation(FD), Logit-Level Distillation(LD) 3가지 모듈
연산 순서
(1) BEV-FPD
- BEV에서 Feature-Pyramid로 특징 추출

(2) Position Guided Feature Fusion Module(PGF2M)
- 카메라와 라이다 각각의 Feature는 상대적인 포지션 정보(?)로 통합된다

(3) Online Camera-to-Lidar Distillation
- Camera-Lidar Fusion 모델(Teacher)로 부터 학습하는 Lidar 기반 모델(Student) 을 제안
- BEV Feature는 연속적인 TreeFilter(?)에 공급되어 Low-High로 affinity map(?)을 생성
- Feature Distillation은 Lidar와 Fusion 특징에서 생성된 Affinity Map에서 수행

로스 함수

성능
- 이하 nuScene Map Segmentation 성능

총평
- 이하 2가지는 이해하기 어려웠다.
- 논문에 나오는 상대적인 포지션 정보로 Fusion 하는 방법(PGF2M)
- Camera-Lidar Fusion 모델(Teacher)로 부터 학습하는 Lidar 기반 모델(Student)의 Distillation 방법
- 코드가 올라가 있지 않음
- 완성차 마다 Map 정의가 달라 일반적인 방법은 아닐 수 있다.
※ 단순 Fusion과 Distilation의 차이
(★) 103. TARL: Temporal Consistent 3D LiDAR Representation Learning for Semantic Perception in Autonomous Driving, Lucas Nunes, Louis Wiesmann, Rodrigo Marcuzzi, Xieyuanli Chen, Jens Behley, Cyrill Stachniss
해결하고자 하는 문제
- 포인트 클라우드 라벨링은 노동과 시간이 많이 필요한 문제
- Self-Supervised 학습으로 PreTrained 된 모델을 제공하여 라벨링 공수를 줄인다
주요 컨트리뷰션
- 같은 오브젝트의 다른 시점의 뷰를 비지도 학습으로 학습하여 Point Representation 성능을 높였다.
- 같은 객체에 대한 시간적 관점을 추출.
- 라이다 스캔을 모와서 지면을 제거하고, 남은 포인트 들을 클러스터링하여 Self-Supervised 학습에 사용할 객체들을 정의하였다.
- 위의 Self-Supervised 학습으로 훈련된 모델을 다양한 DownStream 테스크에서 FineTune하여 성능 평가
- 본 논문 제안 방식이 Semantic 인식에서 라벨링 공수를 크게 줄여줌을 확인

성능
- Semantic Segmentation에서는 라벨링을 10%만 하여도, 라벨링을 100% 하여 Supervised로 학습한 모델과 성능이 유사
- Panoptic Segmentation에서는 라벨링을 50%만 하여도, 라벨링을 100% 하여 Supervised로 학습한 모델과 성능이 유사
총평
- 코드가 주석과 함께 잘 정리되어 있어 살펴보면 라이다 Self-Supervised 학습 참고에 큰 도움이 될 듯함
방법 상세
(1) 스캔 모음(Scan Aggregation): N개의 스캔 집합을 동일한 좌표 축으로 정합한다
- 여기서 N개 스캔 집합의 인덱스는 추후를 위해 따로 저장한다

(2) 지면 제거
- 지면을 제거하면 객체들은 서로 분리되어 있는 특성을 이용한다

(3) 클러스터링 & Temporal View 취득
- 지면을 제외한 포인트 들을 클러스터링
- 동일 객체에 대해 다른 관점에서 취득한 포인트 들을 수집할 수 있게 된다.


(4) Self-Supervised 학습
- 다른 관점의 동일한 군집 객체들은 동일한 포인트로(Positive) 그외는 다른 포인트로(Negative) 학습


105. RangeViT: Towards Vision Transformers for 3D Semantic Segmentation in Autonomous Driving, Angelika Ando, Spyros Gidaris, Andrei Bursuc, Gilles Puy, Alexandre Boulch, Renaud Marlet
주요 컨트리뷰션
- ImageNet 혹은 CityScape 영상 데이터 셋 학습된 ViT 모델을 포인트 클라우드의 Range Image에 적용
- 다른 2D Projection 기반 Segmentation 모델 대비 높은 mIoU 달성
- ViT의 Inductive Bias 부족을 컨볼루션 Stem(?)으로 보완
- 디코더와 컨볼루션을 연결하여 컨볼루션의 Fine-Grained 특징과 트랜스포머의 Coarse한 (대략적인) 특징과 결합
※ 포인트 클라우드 Range Image 참고: https://towardsdatascience.com/spherical-projection-for-point-clouds-56a2fc258e6c
총평
- Projection 기반 PointCloud Segmentation은 포스터에서도 나와있듯이 3D Voxel 기반 SemanticSegmentation 대비 성능이 떨어짐.
- 하지만, 추론 속도가 3D Voxel 기반 대비 빠르고, 파라미터수도 적기 때문에 동향을 지켜볼 필요는 있음

(수-오전)
107. Instant Domain Augmentation for LiDAR Semantic Segmentation, Kwonyoung Ryu, Soonmin Hwang, Jaesik Park
해결하고자 하는 문제
- 라이다 도메인이 달라질 때 Semantic Segmentation 성능이 떨어지는 문제
(e.g. 64bit데이터 취득 후 32bit데이터에서 추론, Velodyne데이터 학습 후 Ouster로 취득한 데이터에서 추론)
주요 컨트리뷰션
- 상이한 도메인에서도 강인한 라이다 데이터 증강법 제기
- 4가지 단계로 구tjd
(1) 라이다 Frame으로 부터 World 모델 구성(라이다 Scan을 통합하여 맵 형태로 만든 것을 지칭하는 것으로 보임)
(2) 랜덤 Lidar Configuration, Poses로 RangeMap 생성
(3) Lidar Distortion을 임의로 부여
(4) 센서 레벨 믹스
(90도는 벨로다인, 270도는 Ouster 것을 사용하는 식으로 센서별 포인트 클라우드 Mix)
총평
- 기업 과제라 코드를 제공하지 않음
- 포스터에 각 단계가 시각적으로 잘 설명되어 있음

(이하 3개의 논문은 개인적으로 설명이 명확하지 않거나, 큰 기여는 아닌 것 같은 사견으로 포스터만 첨부)
108. Less Is More: Reducing Task and Model Complexity for 3D Point Cloud Semantic Segmentation, Li Li, Hubert P. H. Shum, Toby P. Breckon

109. MarS3D: A Plug-and-Play Motion-Aware Model for Semantic Segmentation on Multi-Scan 3D Point Clouds, Jiahui Liu, Chirui Chang, Jianhui Liu, Xiaoyang Wu, Lan Ma, Xiaojuan Qi

110. 3D Semantic Segmentation in the Wild: Learning Generalized Models for Adverse-Condition Point Clouds, Aoran Xiao, Jiaxing Huang, Weihao Xuan, Ruijie Ren, Kangcheng Liu, Dayan Guan, Abdulmotaleb El Saddik, Shijian Lu, Eric P. Xing

(목-오전)
106. Single Domain Generalization for LiDAR Semantic Segmentation, Hyeonseong Kim, Yoonsu Kang, Changgyoon Oh,
Kuk-Jin Yoon
▶ 요약
- Lidar semantic Segmentation을 위한 싱글 도메인 일반화 방법을 제안(보지 못했던 도메인 까지 성능을 발휘하기 위함) (DGLSS)
- SIFC(Sparsity invariant feature consistency)는 기능 선호도를 기반으로 소스 도메인의 희소한 내부 기능을 확장된 도메인과 Align 한다
- SCC(Semantic Correlation Consistency) 의 경우 클래스 프로토타입간의 상관관계가 모든 Lidar 스캔에 대해 유사하도록 제안

▶ 방법
(1) 싱글 도메인 Ps에서 새로운 도메인 Pa로 증강(Augment)
(2) 두 도메인은 Φenc로 인코딩되고 인코딩된 내부 Feature Fs 및 Fa는희소성 불변 기능 일관성(SIFC)(?)으로 제한된다.
(3) Φdec는 Metric Learner Ψ에 공급되어 Feature Embedding 공간을 생성
(4) 임베딩 공간은 SCC(Semantic Correlation Consistency) 에 의해 제한(?) 된다.
(5) Semantic 예측 Ys, Ya는 GT와 Augmented GT에 의해 지도 학습 된다.
▶ 총평
- 코드가 아직 업로드 되지 않아, 방법에 신뢰가 되지 않음
109. GrowSP: Unsupervised Semantic Segmentation of 3D Point Clouds, Zihui Zhang, Bo Yang, Bing Wang, Bo Li
--> 실내 포인트 클라우드 대상
105. LaserMix for Semi-Supervised LiDAR Semantic Segmentation, Lingdong Kong, Jiawei Ren, Liang Pan, Ziwei Liu
[Best Student Paper] 121. 3D Registration With Maximal Cliques, Xiyu Zhang, Jiaqi Yang, Shikun Zhang, Yanning Zhang
TBA
[Best Paper] 131. Planning-oriented Autonomous Driving, Yihan Hu, Jiazhi Yang, Li Chen, Keyu Li, Chonghao Sima, Xizhou Zhu, Siqi Chai, Senyao Du, Tianwei Lin, Wenhai Wang, Lewei Lu, Xiaosong Jia, Qiang Liu, Jifeng Dai, Yu Qiao, Hongyang Li
TBA
Self-supervised learning (자기지도학습)과 Contrastive learning (대조학습)
참고)
https://sanghyu.tistory.com/184
Self-supervised learning (자기지도학습)과 Contrastive learning (대조학습): 개념과 방법론 톺아보기
** 본 포스팅은 NeurIPS2021의 self-supervised learning 튜토리얼에 필자의 소소한 설명을 덧붙인 글입니다. Supervision을 위한 대량의 labelled data 특히 high-quality의 labelled data를 얻는 것은 비용이 많이 든다. u
sanghyu.tistory.com
- unsupervised learning을 통해 좋은 representation을 얻는다면 다양한 downstream task에 빠르게 적응할 수 있을 것이다, 더 나아가서는 supervision보다 더 좋은 성능을 얻을 수 있을 것이다" 라는 생각에서 self-supervised learning 연구들은 출발
- unsupervised learning이라고 볼수도 있지만 label(y) 없이 input(x) 내에서 target으로 쓰일만 한 것을 정해서 즉 self로 task를 정해서 supervision방식으로 모델을 학습하기 때문에 self-supervised learning이라고 많이 부르고 있다.
- 그래서 self-supervised learning의 task를 pretext task(=일부러 어떤 구실을 만들어서 푸는 문제)라고 부른다.
- pretext task를 학습한 모델은 downstream task에 transfer하여 사용할 수 있다. self-supervised learning의 목적은 downstream task를 잘푸는 것이기 때문에 기존의 unsupervised learning과 다르게 downsream task의 성능으로 모델을 평가한다.
-

'논문 리뷰(Paper Review)' 카테고리의 다른 글
| Spherical Transformer for LiDAR-based 3D Recognition (0) | 2023.08.29 |
|---|---|
| Scribble-Supervised LiDAR Semantic Segmentation (0) | 2023.07.27 |
| Unsupervised Domain Adaptation by Backpropagation(in ICML'15) (0) | 2023.05.11 |
| CMRNet++: Map and Camera AgnosticMonocular Visual Localization in LiDAR Maps (0) | 2023.02.04 |
| 2DPASS: 2D Priors Assisted SemanticSegmentation on LiDAR Point Clouds (0) | 2022.10.21 |



