1. 초록
- 기존의 Lidar Segmentation 방법은 2D 프로젝션 후에 수행되며 이는 3D Topology와 기하학적 관계 정보를 버리게 된다.
- 차선의 방법인 3D Voxelization과 3D Convolution은 개선이 제한적이다. 왜냐하면, Point Cloud의 희소성과 밀도의 다양성 때문.
- 원기둥 형태의 비 대칭적 3D Convolution Network를 제안한다. 또한, point-wise 정제 모듈을 제안하여 Voxel 기반 레이블 인코딩에서 발생하는 간섭을 경감 시켰다.
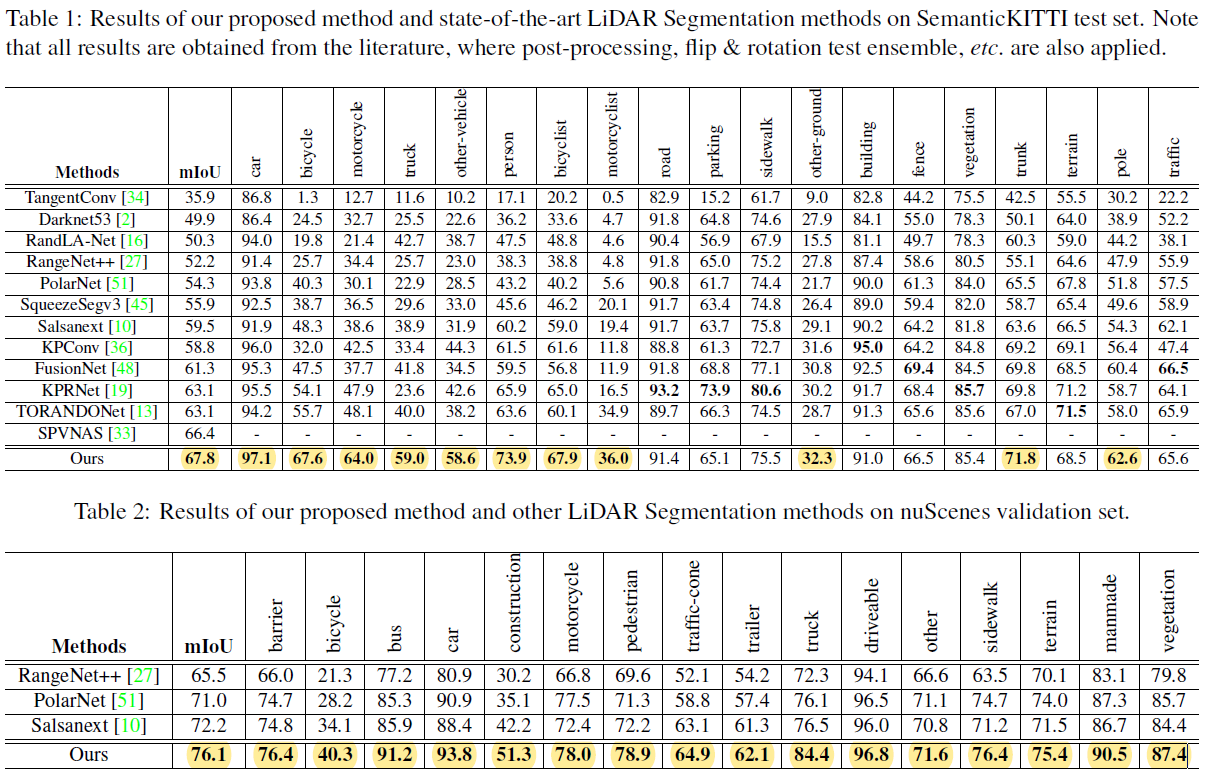
- SemanticKITTI와 nuScenes 에서 1st를 하였다. 기존 대비 4% 성능 개선.
- 제안하는 방법은 LIDAR Panoptic Segmentation과 3D Detection도 잘 수행.
2. 서문
- 2D로 프로젝션 하여 Segmentation을 수행하는 것은 'Rangenet++', 'Squeezeseg' 가 있다.
- Bird-Eye 로 프로젝션 하여 수행하는 것은 'Polarnet' 가 있다.
- Voxelization을 이용하는 것은 '3d semantic segmentation with submanifold sparse convolutional networks', '3d u-net' 등이 있다.
- Indoor Scene은 포인트 클라우드가 상대적으로 Dense하고 Uniform-Density하여 Voxelization이 적합할 수 있다. 하지만, Outdoor Scene은 Sparsity 하고 Vary-density한 특성으로 인해 효과가 떨어진다.

(a) Cylindrical Partition이 Cubic Partition 대비 점 분산이 더 발란스가 잡혀있다(89%, 61%)
(b) 3D Voxel Partition과 3D Conv를 직접적으로 적용하면, 프로젝션에 기반한 2D 방법보다 성능이 떨어질 수 있다(표와는 다른 얘기를 하고 있다...)
- 복셀 기반 방법은 카테고리가 다른 포인트를 동일 셀로 포함시킬 수 있으며, 셀 레이블 인코딩(?)으로 인해, 정보 손실이 필연적으로 발생하게 된다.
- SemanticKITTI 에서 1st를 달성하였다. 또한, 원기둥 형태의 비대칭적 3D Conv를 Lidat Panoptic Segmentation & 3D Detection 으로 까지 확장 시켰다.
<이하 3D Point Cloud를 2D Grids로 변환해서 사용한 논문 들>
- Efficient semantic segmentation of large-scale point clouds. In CVPR 2020
- Salsanext: Fast, uncertainty-aware semantic segmentation of lidar point clouds for autonomous driving, 2020
- Rangenet++: Fast and accurate lidar semantic segmentation, IROS 2019
- 3d-mininet: Learning a 2d representation from point clouds for fast and efficient 3d lidar semantic segmentation, 2020
- Deep fusionnet for point cloud semantic segmentation. ECCV 2020.
- Large-scale point cloud semantic segmentation with superpoint graphs. In CVPR 2018.
<이하 3D Point Cloud를 Bird-Eye View로 프로젝션하여 2D Conv 적용한 논문 들>
- Polarnet: An improved grid representation for online lidar point clouds semantic segmentation, CVPR 2020.
<이하 3D Voxel Partition을 적용한 논문 들>
- Occuseg:Occupancy-aware 3d instance segmentation. In CVPR 2020
- Segcloud: Semantic segmentation of 3d point clouds. In 3DV 2017
- 3d semantic segmentation with submanifold sparse convolutional networks, In CVPR2018
- 3d u-net: learning dense volumetric segmentation from sparse annotation. In MICCAI 2016.
- Vv-net: Voxel vae net with group convolutions for point cloud segmentation. In ICCV 2019.
2D Segmentation에서 U-Net의 높은 성능으로 인해 Lidar Segmentation에서도 U-Net 구조를 적용하였다.
3. 방법
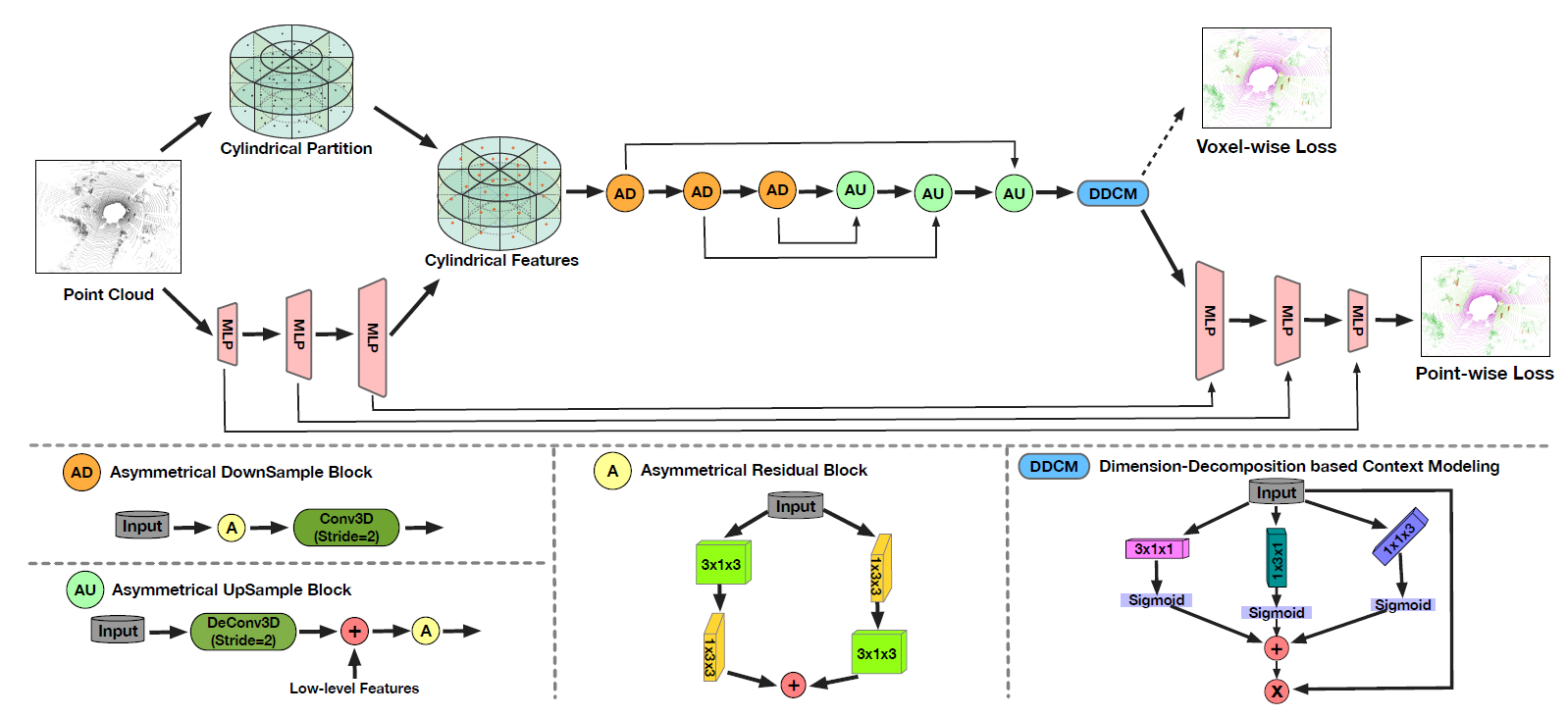
- Lidar Point Cloud는 MLP을 통과하여, point-wise feature를 얻고, Cylinderical Partition에 재할당된다. 비대칭적 3D Conv는 voxel-wise 출력을 내기 위해 사용된다. 마지막으로 Point-Wise 모듈이 출력을 개선(?) 하기 위해 도입된다.
- 비대칭 3D 컨볼루션 네트워크를 사용해서 Voxel-Wise 출력을 생성한다. Loss Cell-label 인코딩 간섭을 완화하기 위해 Point-Wise 모듈이 도입되어 출력을 개선한다.
- 거리가 멀수록, 원기둥 파티션은 그리드 크기가 증가하여 비어 있지 않은 셀 비율이 균형 잡힌 비율을 유지한다.
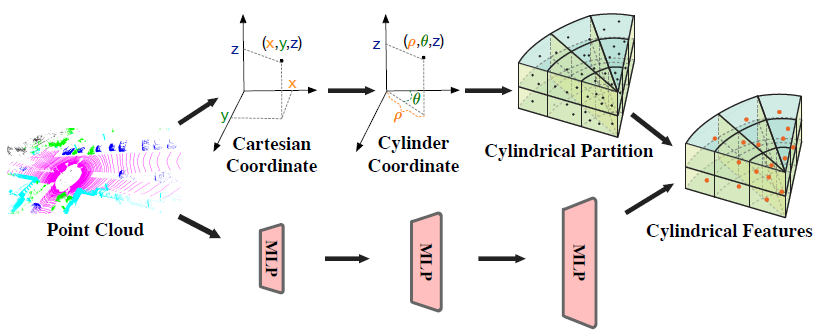
3-1) 좌표 변환 + Cylindrical Feature 변환
- Cartesian 좌표계를 Cylindar 좌표계로 변환한다.
- MLP에서 얻은 Point-Wise Feature를 원통형 파티션을 기반으로 하는 Structured Representation에 할당되어 Cylindrical Features를 얻는다.
3-2) UpSample 블록 + DownSample 블록 + Residual 블록
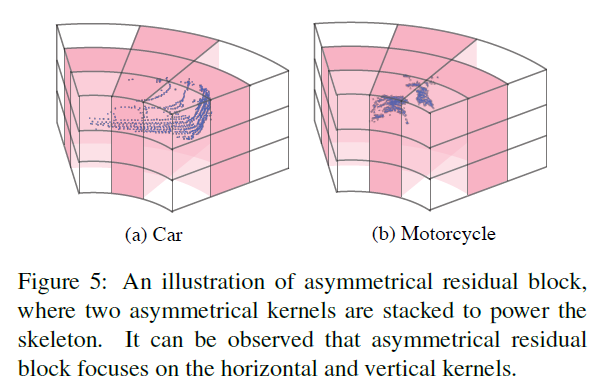
- 수평/수직 응답을 강화하고, Object Point Distribution을 매칭하기 위해(?), 비 대칭 Residual Block을 고안한다. 제안된 비 대칭 Residual 블록을 기반으로 비 대칭 DownSample 블록과 UpSample 블록을 추가로 구축한다.
- 또한, 컨텍스트 모델링에 기반한 차원 분해(DDCM)(?)을 도입하여 분해/합계 전략에서 High-Rank 글로벌 컨텍스트를(?) 찾는다.
- 비대칭 Residual Block으로 인해 수평/수직 응답이 강화된다고 말하고 있다(아래 그림 참조)
3-3) DDCM, Dimension-Decomposition based Context Modeling
- 전역 문맥 특징 정보들은 높은 문맥 다양성을 포함하기 위해 High-Rank(?) 일 것이므로, 이러한 특징을 바로 파악하기란 어렵다.
- 텐서 분할 이론을 도입하여 높은 랭크의 문맥 정보를 저 랭크 텐서로 분할 하였다.
- 3개의 Rank-1의 커널을 사용하여 낮은 Rank의 특징을 얻은 다음 합쳐서 전역 문맥 정보를 얻었다.
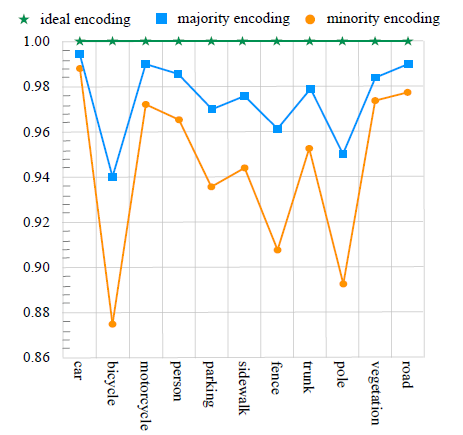
- 파티션에 기반한 방법은 한 셀에서 하나의 라벨을 예측한다. 파티션에 기반한 방법이 넓은 범위의 PCD를 확인할 수 있지만, Cube-Based, Cylinder-Based는 불가피하게 셀 라벨 인코딩 시에 정보 손실이 있다.
- 예를 들어 한 파티션에 두개의 라벨 정보를 가진 포인트가 있으면, 정보의 손실이 있다.
- (아래 그림) (정확한 그림의 의미는 모르겠으나, 한 셀에서 두개의 클래스를 가지는 객체 정보가 있을 경우 포인터를 많이 차지하는 객체로 분류하는 경우와 포인터가 적은 객체로 분류하는 경우의 빈도를 나타낸 듯하다)
3-4) Pointwise Refinement Module
- Voxel-wise 특징을 Point-Voxel 매핑 테이블을 참고하여 Point-Wise 로 프로젝션한다. 다음, Point-Wise 모듈은 3D Conv 네트워크 전/후 Feature를 모두 입력으로 사용하고 융합하여 출력을 정제해 낸다.
3-5) Objective Function
- Loss = Voxel-wise Loss(=weighted cross-entropy loss + lovasz-softmax loss) + Point-wise Loss
- Voxel-wise Loss는 Point Accuracy와 IoU Score를 최대화 하기 위함이다
- Point-wise Loss는 weighted cross-entropy loss가 사용된다.
nuScenes
- 32 채널, 20s 지속으로 1000개의 Scene 수집
- 전체 프레임은 4만장, 20Hz로 샘플링 됨
- 유사 클래스를 합치고, Rare한 클래스를 제거하면 16개의 클래스가 남는다.
(코드 상에서 에러)
- 본 논문의 코드는 디펜던시가 많은데 그 중 하나인 spconv를 1.2 버전(cuda10.2) 에서 사용하였다. 하지만, spconv는 1.x 버전이 deprecated 되었고, 2.x 버전과 1.x 버전은 연산 방법이 다르다고 한다;;;
- 본인이 학습하는 환경은 cuda 11.3 이고 spconv git 레포에 나온 것 처럼 spconv 2.1 버전을 설치한 뒤 본 논문 git에서 제공하는 WEIGHT로 demo_folder.py를 진행하면, 결과가 잘 나오지 않는다. (관련 이슈)
- Cylinder3D_spconv_v2 어떤 분이 spconv 2.x 버전으로 학습을 시켜 가중치를 올려 놓았는데, 아래와 같이 결과가 어느 정도 나오게 된다. 본 논문에 나온 것 처럼 67.x 까지는 가지 못한다.
Validation per class iou:
car : 96.92%
bicycle : 54.25%
motorcycle : 80.25%
truck : 33.20%
bus : 69.36%
person : 45.18%
bicyclist : 59.40%
motorcyclist : 51.25%
road : 95.75%
parking : 55.55%
sidewalk : 86.47%
other-ground : 0.00%
building : 80.21%
fence : 37.01%
vegetation : 89.62%
trunk : 73.00%
terrain : 80.73%
pole : 73.18%
traffic-sign : 73.67%
Current val miou is 65.000
Current val loss is 0.600추가로 변경한 부분
40 epochs
0.001 LR
AdamW with default Weight Decay 0.01 (본 논문에서는 CosineAnnealingLR 이었다)
CosineDecay Schedule
Batch Size 2
- 이하 spconv 1.x 대비 2.x에서 바뀐 부분 --> 입력 채널, 출력 채널 및 커널 크기 순서만 변경되었다고 한다. 또한, spconv 2.x는 index_key가 구분될 필요가 있어서 구분하였다고 한다
(참고: https://github.com/traveller59/spconv/blob/master/docs/SPCONV_2_BREAKING_CHANGEs.md )



