1. 개요
- 55.1AP on COCO test-dev with 77M parameters and 410B Flops
- 최신 대비 4 ~ 9배 파라미터수 적고, 13 ~ 42배 Flops수가 적다.
2. 동기
- 어떤 모델들은 정확도가 높고 파라미터수가 많으며 FLOP수가 크다. 반면, 어떤 모델들은 경량화에 초점을 맞추었다. 본 논문에서는 정확도도 높으면서 효율성이 좋은 (자원 상황에 따라 골라 쓸 수있는) 디택터를 만들고자 하였다.
- One-Stage Detector를 계승하되, 백본, 특징 퓨전, Class/Box 네트워크 등을 고려하여 모델을 고려하다가 두가지 도전적 과제를 발견하였다.
2-1. 과거 동향
MultiScale Feature Representations
- SSD(ECCV 2016), Overgead(ICLR 2014), Unified multi-scale deep cnn for fast OD(ECCV 2016) 등은 피라미드 형태의 백본에서 추출한 Feature 로 부터 예측을 수행하였다.
- Feature Pyramid Network(CVPE 2017)은 FPN을 처음으로 제안하였다.
- STDL은 cross-scale 피처를 활용하는 scale-transfer 모듈을 제안하였다.
- M2det은 Multi-Scale 피처를 합치기 위한 U 모양의 모듈을 제안하였다.
- NAS-FPN은 자동으로 네트워크 토폴로지를 찾아주는 방법이지만, 1000개 가량의 GPU가 필요하며, 결과가 불규칙적이고 해석이 어려운 문제가 있다.
Model Scaling
- 최근 EfficientNet은 네트워크 Width/Depth/Resolution을 결합하여 Scale-Up 하여 분류에서 큰 성능 향상을 보여주었다.
또한, 기존의 방법들은 피라미드 상의 모든 피처를 동일한 기여도로 보았다.
3. 기존 방식의 문제점
- (1) 피처 피라미드의 (각 스케일로 부터 얻은) 다른 Input Feature에서 융합을 할 때, 기존의 방법들은 단순이 합한다. 하지만, 해상도가 각기 다른 Input Feature는 각기 다른 기여도로 융합되는 것을 확인하였다(각 해상도 특징을 충분히 활용하는 것이 아니라, 몇몇 해상도가 Input Feature의 역할을 맡게 된다)
- (2) 피처 네트워크와 Box/Class 예측 네트워크를 스케일링 Up 하는 것은 정확도와 효율성이 치명적인 것을 확인하였다.
4. 방법
- Efficient multi-scale feature fusion: FPN에서 각 해상도별 기여도가 공평하게 분배되지 않는 문제를 해결하기 위해 양방향-FPN을 제안한다(반복적으로 Top-Down, Bottom-Up Scale Fusion을 적용한다)
- Compound Scaling: 모든 백본/피처 네트워크/Box-Class 네트워크에 대해 해상도/깊이/너비를 복합적으로 Scale-Up 하는 방법을 제안한다.
4-1. 방법 자세히
▶Cross-Scale Connections
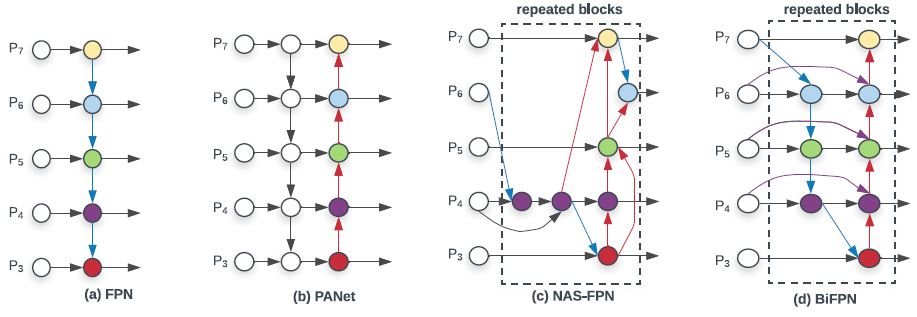
(a) 기본적인 FPN
- 한 반향으로만 정보가 흐르는 한계가 있다.
(b) BottomUp Path 추가
- 양방향 정보 흐름 추가
(c) 자동으로 네트워크를 찾아주는 NAS-FPN
- 찾는데 시간이 오래 걸리며, 출력 모델은 모양이 불규칙적이다.
(d) 본 논문 제안 방법
- Cross-Scale 연결
- 하나의 입력 Edge만 가지는 노드를 제거하였다(노드에 하나의 입력만 있고 특징 융합이 없으면 다른 피처를 융합하는데 기여하기 힘들다는 판단이었다)
- 동일한 레벨에 있는 경우 오리지널 입력에서 출력 노드로의 엣지를 추가(?)하였다
- PANet과 다르게 양방향의 (Top-Down, Bottom-Up) 경로를 여러번 반복하였다.
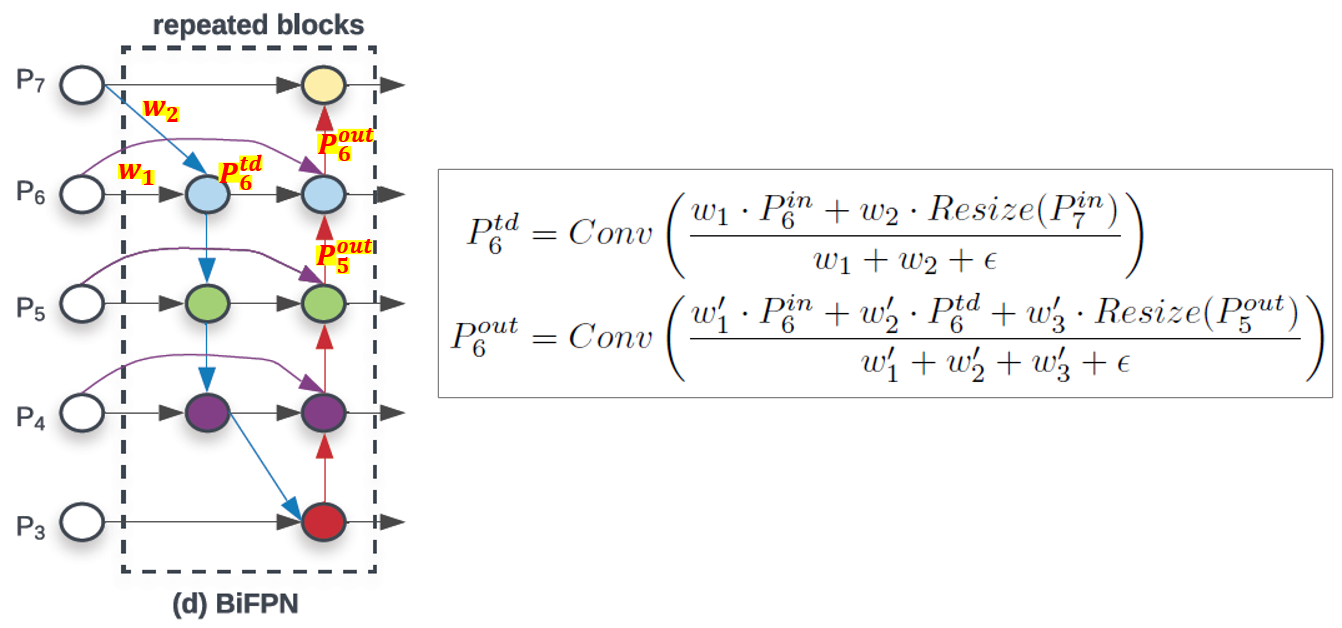
▶Weighted Feature Fusion
- 각 입력 피처에서 중요한 것은 더 학습을 잘 할 수 있게 가중치를 주었다.
- 3가지 Weighted Fusion 접근법을 생각해 내었다. 그 중 3번째 접근법을 사용하였다.
1. Unbounded Fusion
- w는 스칼라(피처별), 벡터(채널별), 다차원 벡터(픽셀별) 일 수 있다. 하지만, 스칼라(피처별 가중치를
주는 것이)가 성능이 좋았다.
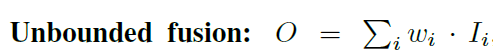
2. Fast normalized fusion
- 위의 방식에서 더 나아가면, 가중치를 정규화한다.

3. 최종
- Bi-Directional Cross-Scale 연결과 Fase-Normalized Fusion을 통합하였다.
또한, Depthwise Seperable Conv를 피처 융합할 때 사용하였다. 그리고 각각 Conv 마다 BN을 사용하였다.
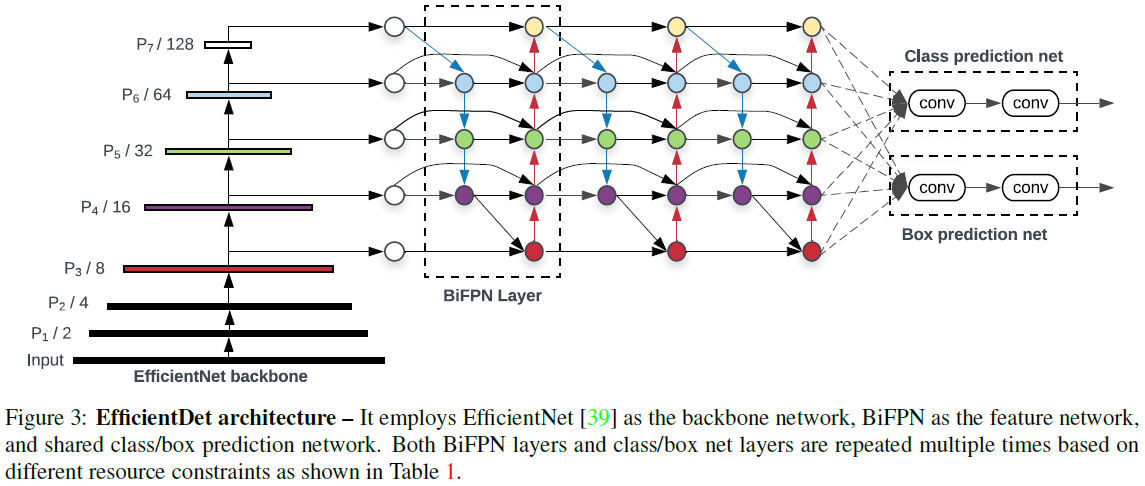
▶ 전체 구조
- 이미지넷 학습한 EfficientNets을 백본으로 사용하였다.
- 3 ~ 7번 피처를 뽑았다. 그리고 Bi-Direction FPN 네트워크를 반복 적용하였다.
- Focal Loss 방법과 유사하게, Class와 Box 네트워크 가중치는 모든 레벨의 피처에 걸쳐서 공유된다.
▶ Compound Scaling
- 기존의 ResNeXt, AmoebaNet 등과 같은 경우는 큰 이미지 입력을 사용하거나, FPN을 스택하는 방법들을 사용하였다. 하지만, 본 방법들은 single or limited 스케일링 차원(?) 에만 집중한다.
- EfficientNet은 네트워크 width, depth, input Resolution 등 네트워크 모든 차원을 Scale-Up 하여 성능을 높였다.
- Compound 계수 $\phi$를 도입하여, 백본/BiFPN/Class-Box/Resolution 등 네트워크의 모든 차원을 Scale-Up 하였다.
- 분류기와는 다르게 디택터는 훨씬 큰 스케일 차원을 필요로 한다.
- 따라서, 모든 차원을 Gird Search 하는 것은 거의 불가능하다(?) (뭘 Grid Search 한다는 것인지?)
- 대신, heuristic-based scale 접근법을 사용한다.
- width/depth scaling 계수를 B0 ~ B6 까지 재사용하였다. ImageNet ckpt에 재 사용이 가능하다.
▶ BiFPN 네트워크
- 선형적으로 BiFPN depth $D_{bifpn}$을 증가 시켰다. 깊이는 작은 정수로 반올림 되어야 하기 때문이다(?)
- BiFPN width $W_{bifpn}$ 는 지수적으로 증가시켰다(?)
- Gird Search를 수행하였고, {1.2, 1.25, 1.3, 1.35, 1.4, 1.45} 중에서 1.35가 BiFPN width scale factor로 적합함을 확인 하였다.
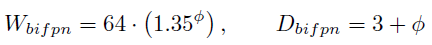
▶ Box/Class 예측 네트워크
- $W_{bifpn}$ 와 $W_{pred}$ 는 항상 동일하게 맞추었다(?)
- 하지만, 아래 공식을 이용해서 선형적으로 증가 시켰다.
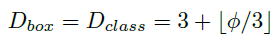
▶ 입력 이미지 해상도
- 가장 높은 위치의 이미지가 128로 나누어 떨어져야 하므로 이미지는 128의 배수가 되어야 하기 때문에
아래 공식에 따라 D0 ~ D7으로 모델을 나누었다.
- Compound 계수 $\phi$는 Heuristic 하게 정한 것이라 최적의 값이 아닐 수 있다. 하지만, 이러한 방법이 다른 단일 차원 Scale 방법 대비 효율을 증가 시켜 주었다.
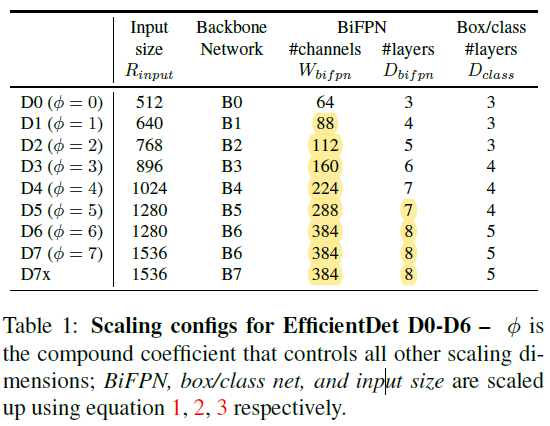
- 공식하고 딱 들어 맞지는 않는다.
5. 성능
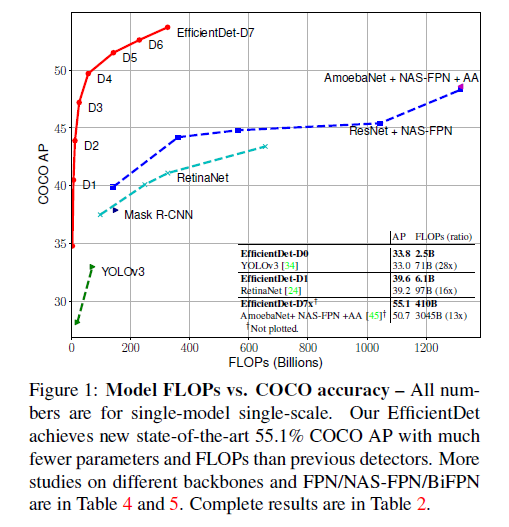
- COCO 데이터 셋에서, Yolov3 보다 28배, RetinaNet 보다 30배, NAS-FPN 보다 19배 적은 FLOP 사용
- 단일 모델, 단일 테스트 시간 스케일(?)로 D7 모델은 55.1AP on COCO test-dev with 77M parameters and 410B Flops 달성
- 최신 SOTA 대비('Learning data augmentation strategies for object detection') 4AP가 높고, 2.7배 경량화 되며, 7.4배 FLOP 수가 적다. 또한, 4 ~ 11배 CPU/GPU 상에서 빠르다.
- PASCAL VOC 2012 기준, 81.74 mIoU, 18B FLOPs 이며 DeepLabV3+ 대비 1.7% 정확도 향상, 9.8배 FLOP수가 적다.
6. 평가
- COCO 2017을 이용하였다.
- D0 ~ D6 모델에 대해 300 epoch, 배치 사이즈 128의 32 TPU v3 코어를 사용하였다.
- 아래는 single-model, single-scale 세팅에서 no TTA 일때 비교한 것이다.
- 정확도는 test-dev(20K test images), val(5k images) 사용
- Latency는 배치 사이즈 1일 때 이다.
- D0 모델이 YOLOv3 대비 28배 FLOP수가 낮았다.
7. 제공 모델
- On Tesla V100(TensorRT X)
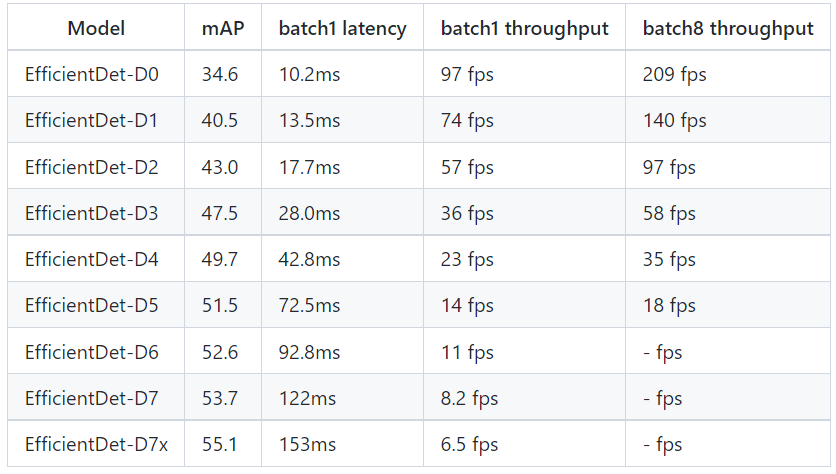
- 이하 경량화된 모델도 제공한다. mAP는 조금 떨어졌다. latency는 더 늘은 것인가(??)
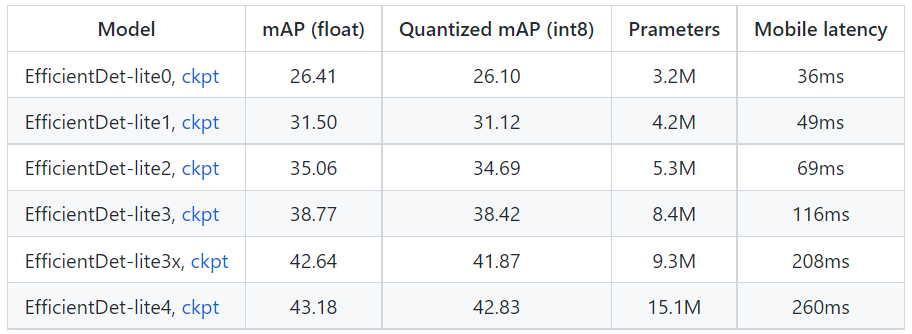
※ Object Detection Compress Models
- [28] Zhuang Liu, Mingjie Sun, Tinghui Zhou, Gao Huang, and Trevor Darrell. Rethinking the value of network pruning. ICLR, 2019. 1
- [29] Jonathan Pedoeem and Rachel Huang. Yolo-lite: a real-time object detection algorithm optimized for non-gpu computers. arXiv preprint arXiv:1811.05588, 2018.



