Abstract
- (2021 기준) ImageNet 에서 90.2%로 기존 방법론(Sharpness-Aware Minimization(SAM), Google, 2021)을 제치고 SOTA를 달성하였다.
- Pseudo Label(2013)과 유사하게 의사 라벨을 생성하여 학생 모델을 가리키는 선생 모델이 존재.
- 하지만, 선생 모델이 고정인 Pseudo Label(2013)과 달리 MLP에서는 학생 성능을 지속적으로 선생 모델에 피드백으로 전달한다.
서론
- 기존 Pseudo Label 단점
: Teacher가 부정확한 경우 → Pseudo label 부정확 → Student는 잘 못된 Pseudo label을 학습
: Student는 Teacher 보다 나아질 수 없음
: 확증 편향(confirmation bias) 발생
: 아래 논문에서 관련 내용을 밝힘
(Eric Arazo, Diego Ortego, Paul Albert, Noel E. O’Connor, and Kevin McGuinness. Pseudo-labeling and confirmation
bias in deep semi-supervised learning. Arxiv, 1908.02983, 2019)
- 본 논문에서는 Teacher에 의해 생성된 의사 라벨이 Student에 어떤 영향을 미치는 지 관찰
: 라벨 데이터에 대한 학생의 성능이 선생에게 피드백으로 전달된다 (학생, 선생 동시 훈련)
(1) 학생은 의사 레이블에서 학습하고
(2) 선생은 학생으로 부터 온 보상 신호를 통해 학습
- 학생/선생 모두 EfficientNet을 사용

- 그 당시 SOTA 보다 성능 우수 + FixMatch, UDA 보다 성능 우수 (!?!?)
[16] (Sharpness-Aware Minimization(SAM), Google, 2021)
[14] (Vit, 2020)

Meta Pseudo Labels 최적화 방안




Meta Pseudo Labels 최적화 - Teacher’s auxiliary losses
- 선생 학습을 지도 학습 + 준 지도 학습 목적 함수로 시켰다.
- 지도 학습의 경우 선생 모델과 라벨 데이터를 이용하였다.
- 준 지도 학습의 경우 라벨링 되지 않은 데이터로 선생 모델을 UDA 목적 함수를 이용해 추가 학습 시켰다.
- 선생 모델은 라벨 데이터와 UDA Loss를 이용해 라벨링 되지 않은 데이터를 추가로 이용하여 학습한다.
- 학생 모델을 선생 모델에서 나온 의사 라벨로만 학습한다.

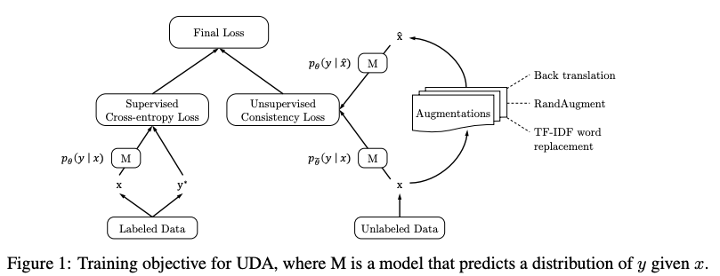
UDA Loss란
결과: Small Scale
- TwoMoon 데이터셋으로 실험
: 지도 학습 - 분류 잘 못함
: Pseudo Labels - 잘못된 의사 라벨을 사용하여 분류기가 잘 못 만들어짐
: Meta Pseudo Labels - 가장 적합한 분류기 찾음

결과: CIFAR104K, SVHN1K, and ImageNet10% Experiments
- 학습 디테일
: 선생과 학생은 같은 아키텍처, 다른 가중치를 사용한다.
: CIFAR-10-4K and SVHN-1K에는 WideResNet-28-2 데이터 셋 사용(1.45 million parameters)
: mageNet-10% 에는 ResNet-50 (25.5 million parameters) 사용
(1) 동시에 teacher와 student 둘 다 학습
(2) Meta Pseudo Labels 학습 완료 후, labeled dataset으로 the student를 finetune
- SGD - 고정 Learning Rate ( 10−5 )
- Batch Size : 512
| Labeled 데이터 | UnLabeled 데이터 | Test 데이터 | Img Size | |
| CIFAR-10-4K | 4K (클래스당 400개) | 41K | 10K | 32 x 32 |
| SVHN-1K | 1K (클래스당 100개) | 603K | 26,032 | 32 x 32 |
| ImageNet-10% | 142K (클래스당 약 142), 10% | 1280K (90%) | 50K | 224 x 224 |

- MPL이 UDA 성능 보다 나음
- MPL은 라벨된 데이터 끼리 학습했을 때 보다도 성능 개선
- ImageNet-10%에서 MPL이 UDA 대비 68.07 -> 73.89% 개선
- CIFAR-10-4K 에서는 97.3% 가 최고 성능인데(UDA) 이는 UDA가 본 논문에서 사용한 WideResNet-28-2 대비 17배나 파라미터수가 많은 PyramidNet을 사용하였기 때문. 동일한 WideResNet-28-2 을 사용하면 UDA는 (표에 나온 것 처럼) 94.53% 가량이 나온다. 이는 MPL 대비 2% 가량 낮은 성능!!
- 반면에 ImageNet-10%에 대해 가장 잘 보고된 상위 1정확도는 80.9%이며, 이는 자체 증류 훈련 단계를 사용하는 Sim-CLRv2[9]와 ResNet50보다 32배 더 많은 매개변수를 갖는 ResNet-152 x 3을 통해 달성되었다.
- ResNet50. 아키텍처, 정규화 및 증류에 대한 이러한 개선 사항은 MPL에도 적용되어 결과를 더욱 향상시킬 수 있다.
==> 다시 말해, 벤치마크에서 높은 성능이 나온 일부 모델은 파라미터 많은 것을 사용했을 때 이고, 동일한 네트워크를 사용하였을 때는 MPL이 성능이 좋다는 말!

결과: Large Scale Experiment: Pushing the Limits of ImageNet Accuracy
- 큰 모델, 큰 데이터 셋에서도 통하는지 확인해 본다.
- EfficientNet-L2 를 사용했고, Noisy Student도 사용하여 top-1 이미지넷이 88.4% 나왔었다.
- 전체 라벨링된 이미지 넷을 사용하였고, 라벨링 되지 않은 JFT dataset has 300-> 130 million (의사 라벨 데이터) 을 사용하였다

'논문 리뷰(Paper Review)' 카테고리의 다른 글
| Dall-e 2 및 주변 기술 리뷰 (1) | 2024.02.14 |
|---|---|
| StyleTrasfer 복습 (0) | 2024.02.13 |
| YOLOPv2: Better, Faster, Stronger for Panoptic Driving Perception (1) | 2023.11.05 |
| BEVFusion: Multi-Task Multi-Sensor Fusionwith Unified Bird’s-Eye View Representation, IRCA2023 (0) | 2023.09.24 |
| Voxel Transformer, ICCV2021 (0) | 2023.09.06 |



