현재 기준
DALL·E 3
DALL·E 3 understands significantly more nuance and detail than our previous systems, allowing you to easily translate your ideas into exceptionally accurate images.
openai.com
Imagen: Text-to-Image Diffusion Models (research.google)
Imagen: Text-to-Image Diffusion Models
Imagen unprecedented photorealism × deep level of language understanding unprecedented photorealism deep level of language understanding We present Imagen, a text-to-image diffusion model with an unprecedented degree of photorealism and a deep level of la
imagen.research.google
<목차>
- DALL-E 2 기본 개념
- 방법
- Notation
- Decoder
- Prior: ( 1) Auto-Regressive(AR) Prior, (2) Diffusion Prior
DALL-E 2 기본 개념
방법
- DALL-E 2는 텍스트와 이미지가 같은 CLIP의 벡터 임베딩 공간(joint representation space)를 활용합니다.
- CLIP은 어떤 텍스트(ex. “불 뿜는 트럼펫을 든 강아지”)와 어떤 이미지가 유사할수록 벡터 공간에서 가깝도록 학습되었습니다.
- (1) CLIP을 이용하여 텍스트가 주어졌을 때, 이에 대응되는 이미지 벡터를 생성합니다.
: Clip의 Text Encoder와 Image Encoder를 학습 시킨다.
- Image Encoder : ViT-H/16, 256x256 Images, Width 1280 with 32 트랜스포머 블록
- Text Encoder : casual attention mask를 적용. Width 1024 with 24 트랜스포머 블록
- (2) 이 이미지 벡터를 Condition으로 받아 Diffusion Model이라는 이미지 생성 모델에 집어넣습니다.
: Prior와 Decoder를 학습할 때 Clip Model(눈금 위 모델)은 Frozen으로 학습 시키지 않는다.

Notation
- 데이터 셋
: Encoder - CLIP, DALL-E에서 사용한 데이터 셋 650M Images
: Decoder, Upsamplers and Prior - DALL-E 데이터셋, 250M Images.
- 이미지 x, 텍스트 y가 주어졌을때 임베딩
: zi - CLIP 이미지 임베딩
: zt - CLIP 텍스트 임베딩
- 텍스트로 부터 이미지를 생성하는 두 구성요소
: P(zi | y) - 텍스트 y로 부터 CLIP 이미지 임베딩 생성 (Prior)
: P(x | zi, y) - Prior에서 생성한 zi로 부터 이미지 생성 (decoder)
- 모델 P(x|y): Prior, Decoder 두 구성요소를 쌓아 텍스트 y가 주어졌을 때 이미지 x를 생성한다.
P(x|y)=P(x,zi|y)=P(x|zi,y)∗P(zi|y)P(x|y)=P(x,zi|y)=P(x|zi,y)∗P(zi|y)
Prior
- 텍스트 y로 부터 CLIP 이미지 임베딩 zi를 생성하기 위해 두개의 Prior 모델에 대해 실험 진행
- 텍스트 y로 부터 CLIP 이미지 임베딩( P(zi | y) ) 생성
1) Auto-Regressive(AR) Prior
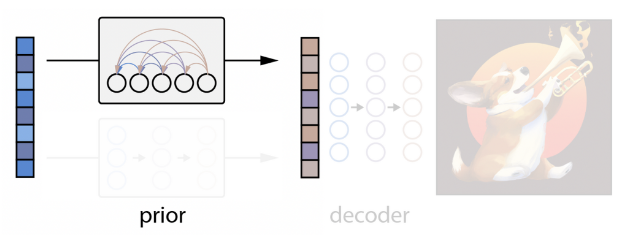
- 텍스트 y를 Discrete Code의 시퀀스로 변환하여 zi 형성. Auto-Regressive 예측
- 효율적으로 학습하고 뽑기 위해 PCA로 zi 차원을 줄임
- CLIP을 SAM Optimizer로 학습하면 Representation Space의 Rank를 굉장히 줄일 수 있음
- 1024중 319개의 Principal Component만 유지해도 거의 대부분 정보 보존 가능
- PCA 적용 후 각 319 차원을 1024개의 Discrete Buckets에 양자화
- 이러한 과정 덕분에 추론 중에 예측되는 토큰 수가 1/3로 줄고, 학습 안정성 향상

2) Diffusion Prior
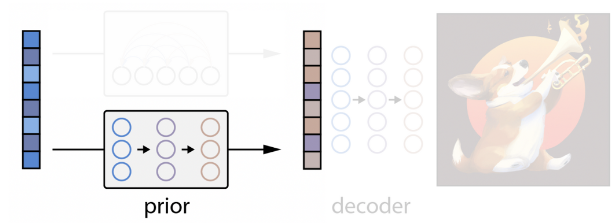
- 연속 벡터 zi를 캡션 y가 조건으로 주어진 가우시안 디퓨전 모델을 통해 재구성
- DDPM에서 사용한 mean-squared error loss 수정해 학습한다.
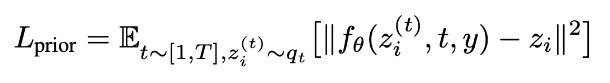
(노이즈가 있는 이미지 임베딩 zi(t)zi(t)와 타임 스탬프 t, 캡션 y를 diffusion prior의 입력으로 두었을 때, 그 출력이 원본 이미지 임베딩 z_i에 가깝에 재 구성되게 하는 Loss이다)
콘텐츠와 스타일 블렌드

캡션을 이용한 이미지 변형

Decoder
- Prior로 만든 CLIP 이미지 임베딩( P(zi | y) )을 조건으로 받아 이미지(x) 생성한다.
- GLIDE의 아키텍처를 수정(3.5B 파라미터 GLIDE 모델)
- 기존 timestep embedding(?)에 CLIP 임베딩을 Projection & Adding
- CLIP 임베딩을 4개의 추가 tokens로 projecting 한 후, 이를 GLIDE 텍스트 인코더의 출력 시퀀스에 Concat
- 고해상도 이미지 만들기 위해 2개의 Diffusion Upsampler Model 학습
참고: What are Diffusion Models? | Lil'Log (lilianweng.github.io)
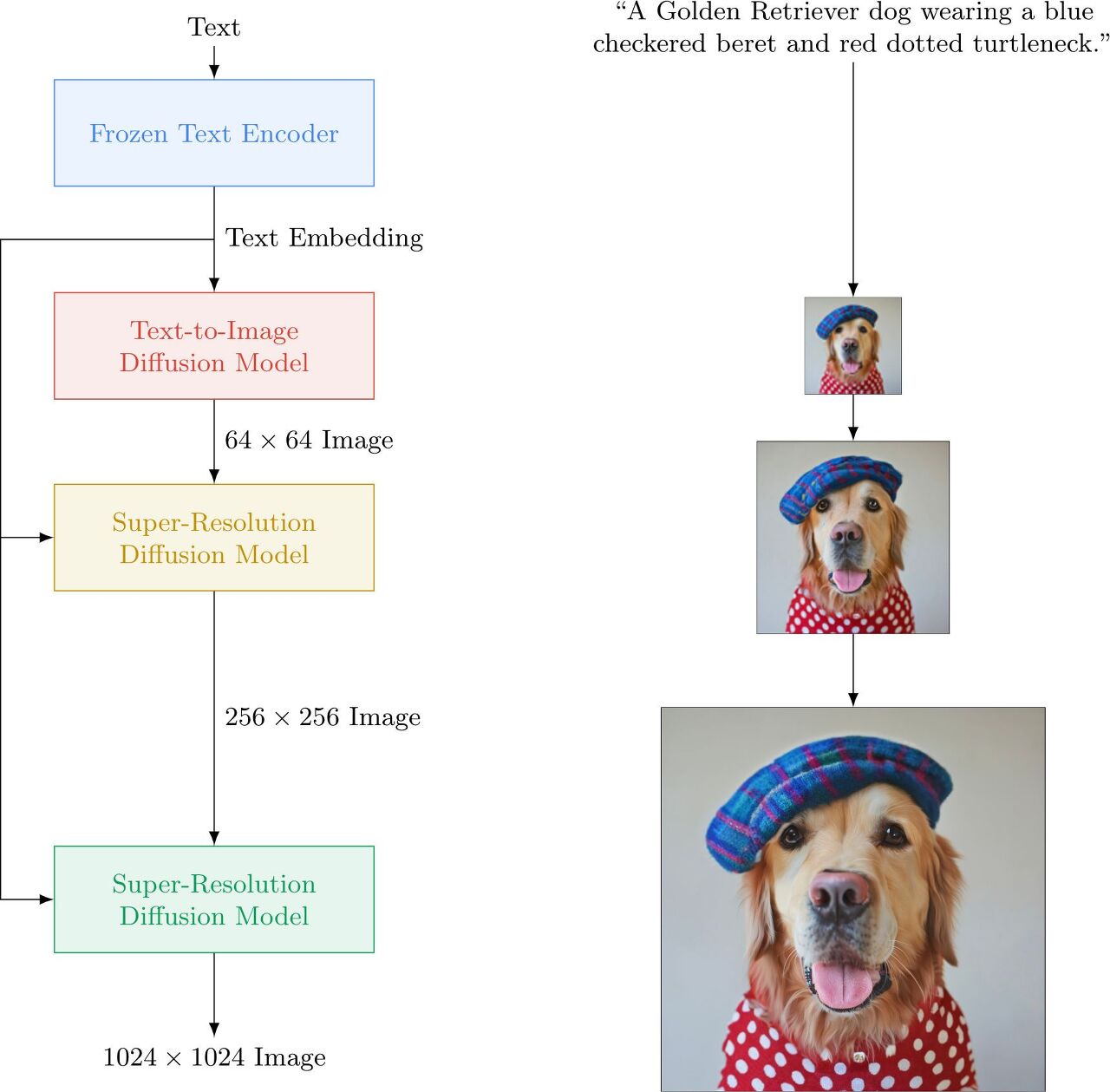
Imagen 기본 개념
- 트랜스포머 기반 텍스트 encoder, diffusion 모델, 그리고 super-resolution 모델을 사용합니다. DALL-E:2와 Parti을 섞어놓은 느낌
- 미리 학습된 T5 언어모델 (간단히 말해 구글 버전의 GPT)를 이용해 텍스트 임베딩을 구한 후, 이를 Diffusion 모델(계단식 DDPM) 로 이미지를 만들어냅니다
- 동적 클리핑 for 향상된 Classifier Free Guidance, 노이즈 레벨 조절 및 메모리 효율적인 UNet 설계
- 생성된 이미지는 작은 편(64x64)인데, 이를 고해상도로 높이기 위해 Super-resolution Diffusion이라는 기술을 사용해 256x256, 1024x1024로 만들어줍니다.
평가 방법
- Fréchet inception distance(FID)는 Inception V3라는 CNN 모델을 공통으로 이용해, 새롭게 생성된 이미지들과 원본 이미지들의 분포 차이값을 계산합니다. 예를 들어, MS-COCO라는 벤치마크 데이터 셋에서 텍스트 캡션을 DALL-E, Imagen, Parti에게 각각 입력하여 이미지를 생성하고, 데이터 셋의 원본 이미지들과 얼마나 비슷한지 계산하는 것

참고)
Diffusion Model 구조
- 시간 t 마다 픽셀 값에 Noise를 첨가 (아주 긴 시간 T번을 거쳐 만든 이미지 X_T는 완전한 Noise 이미지 된다)
- 매 시간 t에 첨가된 Noise를 계산할 수 있다면 과정을 되돌 릴 수 있다.
- 프로세스 t와 조건 Condition (e.g. text)도 확산 모델에게 주어져야 한다.
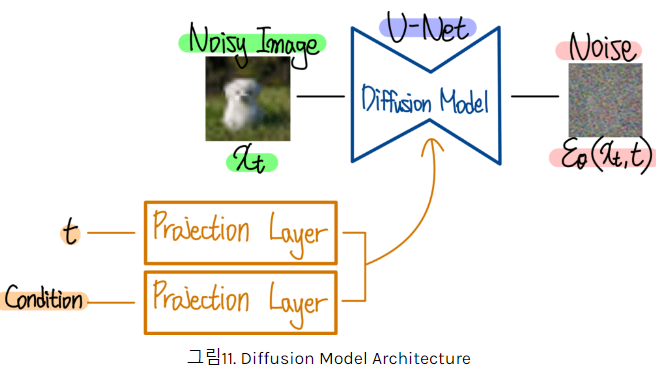
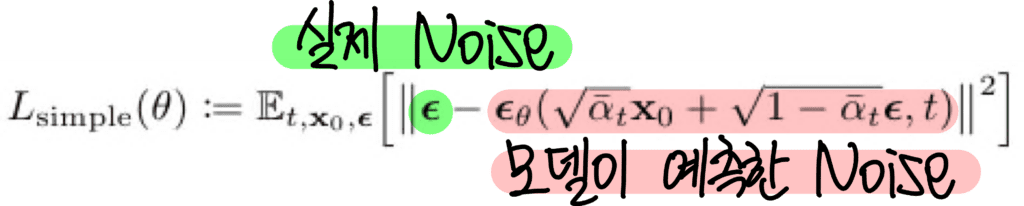
GLIDE 구조
- Text 임베딩을 학습하는 트랜스포머와 이미지 생성을 위한 Diffusion Model, SR을 위한 Diffusion Model로 구성
- 앞의 Diffusion 모델과 다른 부분은 (Text 임베딩을 학습하는 트랜스포머), (SR을 위한 Diffusion Model) 추가
- GLIDE 이후 모델들은 이렇게 Text 임베딩을 따로 학습하지 않고, 대규모 언어로 학습한 Pretrained Text Encoder 사용한다.
- openai/glide-text2im: GLIDE: a diffusion-based text-conditional image synthesis model (github.com)

Imagen구조
- GLIDE와 다른 점은 Pretrained Text Encoder를 사용 + 더 고화질의 SR을 사용했다는 것
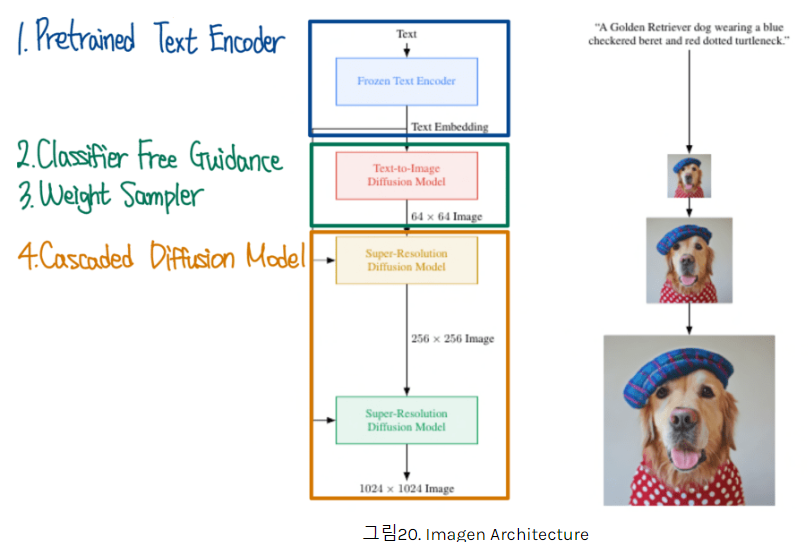
==> Imagen의 Text-To-Image Diffusion Model은 참고할 만 하겠다.
DALLE2 구조
- Pretrained Text Encoder 대신 Contrastive로 학습한 Pretrained CLIP을 사용하여 Text와 Image 임베딩 추출
- Prior와 Decoder로 표현되어 있는 Diffusion Model 사용
- 이미지 생성 뿐만 아니라 이미지 조작(Manipulation) 방법도 제안
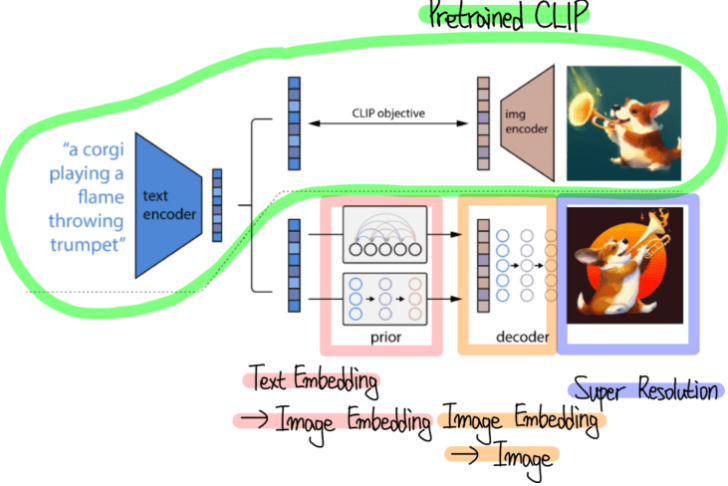
Multi Modal Guided Image Generation
- GLIDE, Imagen, DALLE2는 Text만 조건으로 입력받을 수 있었는데, 다른 입력을 조건으로 받게할 수 있다.

Multi Modal Input Image Generation
- Text, Layout, KeyPoint, DepthMap 등을 동시에 입력으로 받는다.
- 몸통 부분은 Stable Diffusion이 그대로 들어가 있지만, Grounding 정보를 연산하기 위한 Gated Self Attention 부분만 추가되었다.
- GLIGEN은 Stable Diffusion 부분은 Freeze 한 채로 Gated Self Attention 부분만 학습해줍니다.


추가로 볼 만한 것
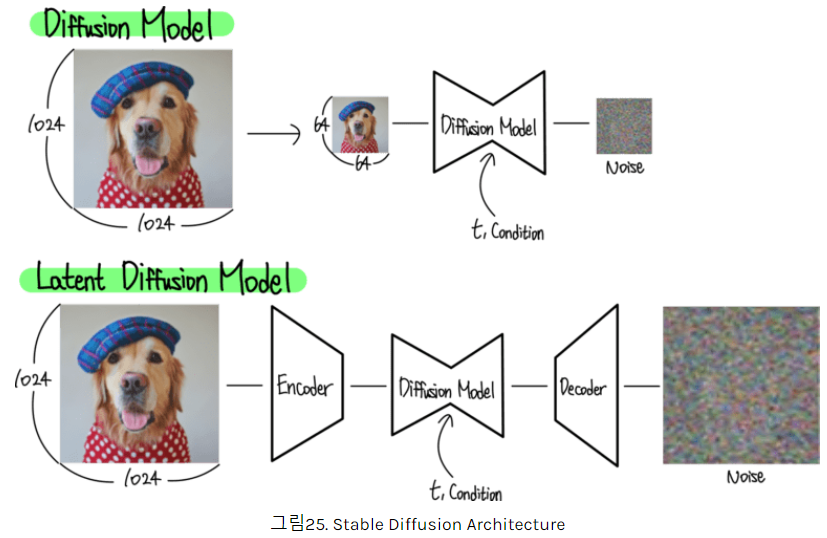
- CompVis/latent-diffusion: High-Resolution Image Synthesis with Latent Diffusion Models (github.com)
GitHub - CompVis/latent-diffusion: High-Resolution Image Synthesis with Latent Diffusion Models
High-Resolution Image Synthesis with Latent Diffusion Models - CompVis/latent-diffusion
github.com
GitHub - Stability-AI/stablediffusion: High-Resolution Image Synthesis with Latent Diffusion Models
High-Resolution Image Synthesis with Latent Diffusion Models - Stability-AI/stablediffusion
github.com
참조
DALLE2 - Diffusion Model 논문 리뷰 (ffighting.net)
DALLE2 - Diffusion Model 논문 리뷰
DALLE2 논문의 핵심 내용을 리뷰합니다. 먼저 기존 방법의 문제점을 살펴봅니다. 이어서 이를 해결하기 위한 DALLE2의 제안 방법을 살펴봅니다. 마지막으로 성능 비교 실험을 통해 DALLE2의 효과를 확
ffighting.net
[논문 리뷰] DALL-E 2 : Hierarchical Text-Conditional Image Generation with CLIP Latents (tistory.com)
[논문 리뷰] DALL-E 2 : Hierarchical Text-Conditional Image Generation with CLIP Latents
최근 OpenAI에서 발표한 Text-to-Image 모델 DALL-E 2의 논문을 리뷰합니다. 작년에 발표한 DALL-E 1 보다 더 사실적이면서, 캡션을 잘 반영하는 고해상도(4x) 이미지를 생성해 많은 관심을 받았습니다. 리
cocoa-t.tistory.com
'논문 리뷰(Paper Review)' 카테고리의 다른 글
| LoRA for Efficient Stable Diffusion Fine-Tuning (0) | 2024.06.17 |
|---|---|
| DDPM(Denosing Diffusion Probabilistic Model) 개념 정리 (0) | 2024.02.27 |
| StyleTrasfer 복습 (0) | 2024.02.13 |
| Meta Pseudo Labels(CVPR 2021) (0) | 2024.01.02 |
| YOLOPv2: Better, Faster, Stronger for Panoptic Driving Perception (1) | 2023.11.05 |



