▣ 개요
- Kitti Odmetry Task에서 제공하는 순서를 그대로 따른다.
- 복셀화된 입력(00 ~ 21번), bin 파일 제공
- 11개(00번 ~ 10번) 순차 데이터 셋에 대해, 학습용 Dense Annotation 제공.
: 00 ~ 10번 폴더만, voxels 폴더에 .invalid, .occluded 파일이 있다. 11번 폴더 이상은 .bin 파일만 있다.
- 11개(11번 ~ 21번)은 평가용. labels 폴더가 없다.

▣ 클래스
- 이동체, 비 이동체 포함, 28개 클래스
- 이동체 8개를 제외하면, 비 이동체는 20개이다.
- 이동체의 경우 관찰(Scan) 하는 동안 이동하면 "Moving"으로 간주하며, 설령 중간에 멈추더라도 여전히 "Moving"으로 간주한다(관련 링크: https://github.com/PRBonn/semantic-kitti-api/issues/80)

- 실제로 semantic-kitti.yaml에 보면, labels은 34개로 나와 있다(?) 여기서 이동하는 객체("Moving") 8개를 빼면, 26개이다.
비 이동체는 20개라고 했는데 왜 26개 일까?
(관련 링크: https://github.com/PRBonn/semantic-kitti-api/blob/master/config/semantic-kitti.yaml)
| labels: | |
| 0 : "unlabeled" | |
| 1 : "outlier" | |
| 10: "car" | |
| 11: "bicycle" | |
| 13: "bus" | |
| 15: "motorcycle" | |
| 16: "on-rails" | |
| 18: "truck" | |
| 20: "other-vehicle" | |
| 30: "person" | |
| 31: "bicyclist" | |
| 32: "motorcyclist" | |
| 40: "road" | |
| 44: "parking" | |
| 48: "sidewalk" | |
| 49: "other-ground" | |
| 50: "building" | |
| 51: "fence" | |
| 52: "other-structure" | |
| 60: "lane-marking" | |
| 70: "vegetation" | |
| 71: "trunk" | |
| 72: "terrain" | |
| 80: "pole" | |
| 81: "traffic-sign" | |
| 99: "other-object" | |
| 252: "moving-car" | |
| 253: "moving-bicyclist" | |
| 254: "moving-person" | |
| 255: "moving-motorcyclist" | |
| 256: "moving-on-rails" | |
| 257: "moving-bus" | |
| 258: "moving-truck" | |
| 259: "moving-other-vehicle" |
- 아래에 보면 "learning_map" 라벨이 있는데, 단일 스캔과 구별할 수 없거나 GT에서 일치하지 않는 클래스는 가장 가까운 클래스에 매핑된다고 나와 있다. 따라서, 전체 비이동체 라벨 갯수는 20개가 된다.
| learning_map: | |
| 0 : 0 # "unlabeled" | |
| 1 : 0 # "outlier" mapped to "unlabeled" --------------------------mapped | |
| 10: 1 # "car" | |
| 11: 2 # "bicycle" | |
| 13: 5 # "bus" mapped to "other-vehicle" --------------------------mapped | |
| 15: 3 # "motorcycle" | |
| 16: 5 # "on-rails" mapped to "other-vehicle" ---------------------mapped | |
| 18: 4# "truck" | |
| 20: 5 # "other-vehicle" | |
| 30: 6 # "person" | |
| 31: 7 # "bicyclist" | |
| 32: 8 # "motorcyclist" | |
| 40: 9 # "road" | |
| 44: 10 # "parking" | |
| 48: 11 # "sidewalk" | |
| 49: 12 # "other-ground" | |
| 50: 13 # "building" | |
| 51: 14 # "fence" | |
| 52: 0 # "other-structure" mapped to "unlabeled" ------------------mapped | |
| 60: 9 # "lane-marking" to "road" ---------------------------------mapped | |
| 70: 15 # "vegetation" | |
| 71: 16 # "trunk" | |
| 72: 17 # "terrain" | |
| 80: 18 # "pole" | |
| 81: 19 # "traffic-sign" | |
| 99: 0 # "other-object" to "unlabeled" ----------------------------mapped | |
| 252: 1 # "moving-car" to "car" ------------------------------------mapped | |
| 253: 7 # "moving-bicyclist" to "bicyclist" ------------------------mapped | |
| 254: 6 # "moving-person" to "person" ------------------------------mapped | |
| 255: 8 # "moving-motorcyclist" to "motorcyclist" ------------------mapped | |
| 256: 5 # "moving-on-rails" mapped to "other-vehicle" --------------mapped | |
| 257: 5 # "moving-bus" mapped to "other-vehicle" -------------------mapped | |
| 258: 4 # "moving-truck" to "truck" --------------------------------mapped | |
| 259: 5 # "moving-other"-vehicle to "other-vehicle" ----------------mapped |
※ Oulier와 Unlabeled 차이
- https://github.com/PRBonn/semantic-kitti-api/issues/17
▣ 폴더 구조 및 포맷
Semantic Segmentation and Panoptic Segmentation
: 출력은 각 점에 대한 레이블 값이다. Single Scan, Multiple Scan 두가지 테스크에 대해서 평가를 하고, Single Scan에서는 Moving/Non-Moving Object를 구분할 필요 없다. 즉, 이동하는 차, 정차된 차 모두 하나의 'Car' 클래스이다. 하지만, Multiple Scan 테스크에서는 '이동하는 차, 정차된 차'를 클래스를 구분한다. 따라서, 더욱 난이도가 있다.
: Panoptic Segmentation 테스크의 경우 Instance까지 추론해야 한다.

XXXXXX.bin은 KITTI Odometry 벤치마크와 동일한 Velodyne 라이다 스캔 파일이다.
: [x, y, z, 반사율(remossion)], float32
XXXXXX.label은 bin파일에 대응되는 각 점의 라벨을 뜻한다. 이진 파일 형식이다.
: uint32(하위 16bit는 라벨 값을, 상위 16bit는 Instance ID 이다)
: InstanceID는 전체 시퀀스에서 동일 물체 여부를 나타내기 위함으로, 스캔 위치가 달라도 동일 객체는 동일한 ID를 갖는다.
: 이동하는 자동차, 루프 클로징 이후 정적 객체도 포함된다.
poses.txt는 Surfel-기반 SLAM으로 추정된 데이터에 주석을 넣기 위한(?) 파일. Annotation Tools에서 사용된 각 카메라 프레임에 대해 수동으로 닫혀 있는(manually looped-closed) 포즈가 포함되어 있다.
※ 코드 참고 : https://github.com/PRBonn/semantic-kitti-api/blob/master/auxiliary/laserscan.py
※ poses.txt 파일의 자세한 설명 : https://dhpark1212.tistory.com/entry/pointlabeler-%EC%A0%95%EB%A6%AC
| 참고) https://github.com/PRBonn/semantic-kitti-api voxel/ 폴더에는 semantic scene completion을 위한 모든 정보를 포함한다. .bin 파일에는 복셀이 Occupied 된 경우 압축된 이진 포맷 레이저 측정치 포함 되어 있다. Semantic Scene Completion Task에서 입력으로 들어가고, 단일 라이다 스캔의 복셀화에 대응된다. .label은 Complete Scene의 각 복셀의 이진 라벨값을 가지고 있다. 라벨은 16bit, uint16_t .invalid, .occluded는 복셀 Occlusion을 포함한다. 유효하지 않은 복셀은 각 View Position에서 가려진 복셀이며, 가져진 복셀은 첫번째 시점에서 가려진다(?) 데이터 리딩: https://github.com/PRBonn/semantic-kitti-api/blob/master/auxiliary/laserscan.py 데이터 로딩: https://github.com/PRBonn/semantic-kitti-api/blob/master/auxiliary/SSCDataset.py |
Semantic Scene Completion
: 단일 초기 스캔(?)에서 특정 볼륨 내부의 완전한 장면(?)을 예측한다. 입력을 복셀 그리드를 사용하고, 각 복셀은 Empty 혹은 Occupied로 마킹된다. Semantic Scene Completion에서는 복셀이 점유되었는지 여부롸 완성된 장면(Completed Scene, 뭘 말하는지..) 에서 라벨을 예측해야 한다.
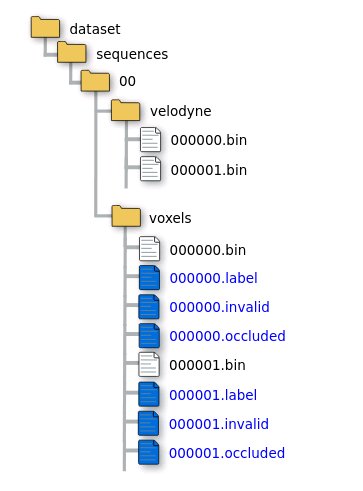
voxels/XXXXXX.bin은 복셀이 레이저 측정에 의해 점유되는 경우(?) 복셀에 포함되는 압축된 바이너리 형식의 파일.
voxels/XXXXXX.label 각 복셀에 대해 이진 형식의 레이블이 포함된 파일. 각 복셀에 대한 unsigned 16bit 정수
voxels/XXXXXX.invalid 각 복셀에 대해 해당 복셀이 유효하지 않은 것으로 간주되는지 여부를 나타내는 플래그를 포함하는 압축된 바이너리 형식의 파일
voxels/XXXXXX.occluded 복셀이 라이다 측정에 의해 점유(Occupied) 되는지 혹은 완료된 장면(?)을 생성하는데 사용된 모든 포즈의 시야에 있는 복셀에 의해 가려(Occluded)지는지 지정하는 플래그가 포함된 바이너리 파일
※ 아래 그림상에서 위의 Task를 즉, 차를 중심으로 단일 스캔 한 영역에서 세그멘테이션 수행한 것을 Semantic Segmentation 이라고 하고, 아래 Task 즉, 맵을 중심으로 한 사각 영역에서 세그멘테이션 수행한 것을 Semantic Scene Completion이라고 일단 이해 하였다.

Semantic Scene Completion 테스크는 입력이 왜 포인트가 아닌 복셀이어야 하는지(?)는 아직 이해하지 못했다.
▣ 평가
- evaluate_{semantics, completion, panoptic}.py 파일로 평가한다.
※ 주의 사항: 메서드가 Cross-entrophy 매핑된 클래스를 학습하는 경우(?), learning_map_inv 딕셔너리(?)를 이용해서 본래 데이터 포맷으로 전송되어야 한다(?). 이는 본래 레이블은 동일하게 유지되기 때문에(?) 데이터 클래스의 관심 변경이 중간 출력에 영향을 주는 것을 막기(?) 위함이다. remap_semantic_labels.py 파일을 제공하여, 학습 전에 이러한 이동이 발생하게 한다(?) 또한, 평가 전에 한번더 Configuration 파일에서 관심 클래스를 선택한다(?)
그외,
- generate_sequential.py 파일을 이용하면 manually looped closed posed(poses.txt 파일) 이용해서 연속된 pcd 파일을 하나로 합쳐둔다.
- remap_semantic_labels.py 파일 이용하면, labels을 cross-entrophy 형태로 혹은 그 반대로 재 매핑해준다. 따라서, 라벨은 학습 혹은 예측 시에 사용될 수 있다. 본 파일은 learning_map 딕셔너리 와 learning_map_inv 딕셔너리를 이용한다.
출처
- http://www.semantic-kitti.org/dataset.html
- http://semantic-kitti.org/tasks.html
- https://github.com/PRBonn/semantic-kitti-api
GitHub - PRBonn/semantic-kitti-api: SemanticKITTI API for visualizing dataset, processing data, and evaluating results.
SemanticKITTI API for visualizing dataset, processing data, and evaluating results. - GitHub - PRBonn/semantic-kitti-api: SemanticKITTI API for visualizing dataset, processing data, and evaluating ...
github.com
※ Lidar 회전에는 (물리적) 시간이 걸리므로 실제로 모든 라이다 빔은 동일 위치에서 발사되지 않는다. 이에 따라, 라이다를 구형(Spherical) 프로젝션 할 경우, 나선형 패턴을 볼 수 있다.
Understanding Spherical Projection · Issue #76 · PRBonn/semantic-kitti-api (github.com)
Understanding Spherical Projection · Issue #76 · PRBonn/semantic-kitti-api
Hello, I've been trying to understand the spherical projection process. I generated the projection mask for a few scans from sequence 00, scans 0-2: I used the following projection parameters: ...
github.com
Project point cloud into spherical projection
Spherical Projection for Point Clouds | by Anirudh Topiwala | Towards Data Science
Spherical Projection for Point Clouds
Spherical Projection of point cloud to image is extremely useful in deep learning. Here I give an in depth explanation with exciting…
towardsdatascience.com
'심화 > 포인트 클라우드 기반' 카테고리의 다른 글
| PCL RGB (0) | 2022.11.07 |
|---|---|
| PCL Window Install (0) | 2022.09.01 |
| [1] Open3D 제공 기능 목록 정리(PointCloud) (0) | 2022.07.14 |
| DBSCAN(밀도 기반 클러스터링) (0) | 2022.06.21 |



