※ 본 포스팅은 아래 링크 문서 및 다수 파이토치 포럼 글을 참고하여 만든것 입니다.
pytorch.org/tutorials/beginner/nlp/sequence_models_tutorial.html
참고) LSTM 설명 포스팅
참고) Time Series Forecasting using LSTM
<Content>
1) LSTM in Pytorch
1-1) Pytorch 사용법
1-2) LSTM 사용시 궁금한 부분과 모은 답변
1-3) Multivariate time series (anomaly) data using LSTM
1) LSTM in Pytorch
"Sequence models are central to NLP: they are models where there is some sort of dependence through time between your inputs. The classical example of a sequence model is the Hidden Markov Model for part-of-speech tagging. Another example is the conditional random field"
--> 시퀀스 모델은 NLP의 핵심이다. 입력 시간에 따라 의존성이 있는 모델.
시퀀스 모델의 고전적인 방법은 Hidden Markov Model 이다. 다른 예시로는 Conditional Random Field가 있다.
"In the case of an LSTM, for each element in the sequence, there is a corresponding hidden state ht, which in principle can contain information from arbitrary points earlier in the sequence. We can use the hidden state to predict words in a language model, part-of-speech tags, and a myriad of other thing"
--> LSTM의 경우 각 요소에 대해 은닉상태 ht가 있다. 시퀀스의 앞부분에서 가져온 정보를 포함할 수 있다.
"Before getting to the example, note a few things. Pytorch’s LSTM expects all of its inputs to be 3D tensors. The semantics of the axes of these tensors is important. The first axis is the sequence itself, the second indexes instances in th mini-batch, and the third indexes elements of the input."
--> Pytorch는 LSTM 입력이 3D 텐서로 가정.
1) 시퀀스 자체
2) 미니배치의 인스턴스 인덱스
3) 입력 요소
[Sequense_length, Mini_Batch_Index, Input_Feature]
1-1) Pytorch 사용법
torch.nn.LSTM(*args, **kwargs)Multilayer LSTM의 경우 입력 $ x_t^{(l)} $는 이전 hidden state 값과 drop 값의 곱이다. 즉,
$$ x_{t}^{(l)} = h_{t}^{(l-1)} * \delta_{t}^{(l-1)} $$
(델타 값은 베르누이 확률로 0을 가진다)
Parameters
- input_size – The number of expected features in the input x (입력 x의 피처 갯수)
- hidden_size – The number of features in the hidden state h, (64)
- num_layers – Number of recurrent layers. E.g., setting num_layers=2 would mean stacking two LSTMs together to form a stacked LSTM, with the second LSTM taking in outputs of the first LSTM and computing the final results. Default: 1 , 본인의 경우 (2)
- bias – If False, then the layer does not use bias weights b_ih and b_hh. Default: True
- batch_first – If True, then the input and output tensors are provided as (batch, seq, feature). Default: False
- dropout – If non-zero, introduces a Dropout layer on the outputs of each LSTM layer except the last layer, with dropout probability equal to dropout. Default: 0
- bidirectional – If True, becomes a bidirectional LSTM. Default: False
- proj_size – If > 0, will use LSTM with projections of corresponding size. Default: 0
Inputs: input, (h0, c0)
input --> (seq_len, batch, input_size) 사이즈를 가지는 입력 텐서
h_0 --> (num_layers * num_directions, batch, hidden_size) 사이즈를 가지는 텐서, 초기 hidden state 값을 가진다.
c_0 --> (num_layers * num_directions, batch, hidden_size) 사이즈를 가지는 텐서, 초기 cell state 값을 가진다.
h_0, c_0가 제공되지 않을 시 0값을 기본적으로 가진다.
Ouput: output, (hn, cn)
output --> (seq_len, batch, num_directions * hidden_size) 사이즈를 가지는 텐서. 출력 피처 h_t를 LSTM 마지막 레이어로 부터 가진다.
h_n --> (num_layers * num_directions, batch, hidden_size) 사이즈를 가지는 텐서
c_n --> (num_layers * num_directions, batch, hidden_size) 사이즈를 가지는 텐서
1-2) LSTM 사용시 궁금한 부분과 모은 답변
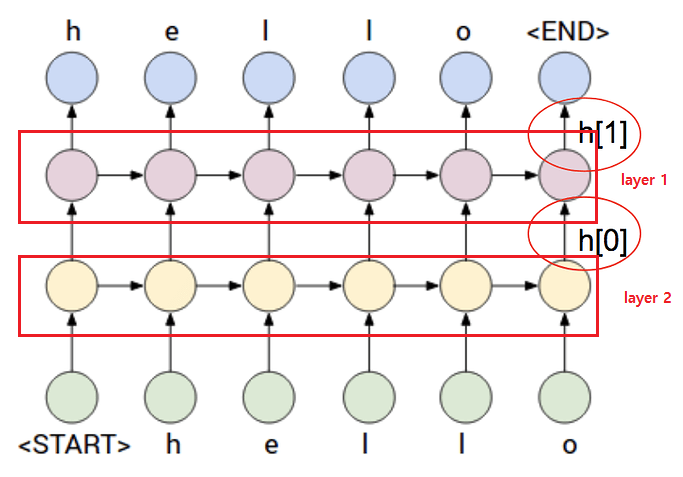
[완료] Q1. num_layer가 2 이상일 경우 네트워크 형태, Hidden State의 의미 (Pytorch포럼 링크) (나의 질문)
- num_layer가 2 이상이 되면 LSTM은 위의 그림과 같이 Stacking 된다.
- 스택 형 LSTM을 사용하면 시퀀스의 recurrent 캡처를 개선하는 데 도움 된다(??)
- hidden state는 단순히 입력의 표현을 늘려주는 역할이다. CNN에서와 같이.
(데이터의 분포를 잘 설명할 수 있으나, 지나치게 늘리면 Over Fitting 된다)
(SO참고 자료)
아래의 두 표현은 같다.
nn.LSTM(input_size, hidden_size, 2)nn.Sequential(OrderedDict([
('LSTM1', nn.LSTM(input_size, hidden_size, 1),
('LSTM2', nn.LSTM(hidden_size, hidden_size, 1)
]))다만, 사람들은 아래와 같이 표현하기도 하는데 그 이유는 각 레이어에서 hidden state를 못 얻기 때문이다(??)
(위에서 출력 값인 h_out = [num_layer, ..., ...] 가 두개의 hidden_output을 나타내는 것이 아닌가??)
rnns = nn.ModuleList()
for i in range(nlayers):
input_size = input_size if i == 0 else hidden_size
rnns.append(nn.LSTM(input_size, hidden_size, 1))만약 당신이 hidden_state의 중간 레이어를 얻고자 한다면, 각 LSTM 레이어를 for 루프로 돌려야 한다.
outputs = []
for i in range(nlayers):
if i != 0:
sent_variable = F.dropout(sent_variable, p=0.2, training=True)
output, hidden = rnns[i](sent_variable)
outputs.append(output) # outputs에는 각 LSTM hidden state를 담게 된다(?? output이 아니고??)
sent_variable = output
[미결] Q2. num_layer > 1 일 경우 출력(h_out , output)이 둘다 [num_layer, ... , ... ] 으로 나온다. Stacking된 두군데 출력 값 모두를 나타내는 건지?
-
[미결] Q3. num_layer > 1일 경우 output이 [num_layer, batch_size, input_feature]가 되어 Fully Connect를 적용하면 [num_layer * batch_size, input_feature] 가 되어 [batch_size, input_feature] 형태를 가지는 Ground Truth와 비교하기 힘든 형태가 되지 않나??
아니면 위의 그림 처럼 h[1] 즉, 뒤에 부분만 사용하여야 하나??
- 예시) num_layer=1 의 경우 h_out : [1000, 128] , num_layer=2 의 경우 h_out : [2, 1000, 128]
- (스택오버플로 비슷한 질문)
-
[완료] Q4. h_output(마지막 hidden_state 출력 값) 을 뽑아서 출력 값으로 사용하는 곳도 있고(링크), Output 을 출력 값으로 뽑아서 쓰는 곳도 있다(링크1, 링크2). 차이가 무엇인가?
- Output이든, Hidden_Cell_output 이든 포함하는 Hidden_Size 축을 Feature_length(혹은 num_classes)로 Fully_Connected를 이용하여 바꾸는 것은 동일하다
- 다만, Output_layer를 리턴 값으로 쓰고자 한다면, Seq_len의 마지막 것만 써야 한다. 즉, Output[-1]
- (내가 받은 답변) lstm_out은 모든 시간 단계(시퀀스의 모든 항목)에 대한 마지막 hidden state를 포함한다.
"last"는 레이어 수와 관련하여 hidden state를 뜻한다. (Q3의 num_layer 갯수에 따라 h_out이 달라지는 것처럼)
반면에 h_out(hidden cell output)은 시간 단계 수와 관련하여 마지막 hidden state를 나타낸다.
num_layer>1인 경우 모든 레이어에 대한 숨겨진 상태가 포함된다.
Case1)
# Propagate input through LSTM
lstm_out, (h_out, _) = self.lstm(x, (h_0, c_0))
h_out = h_out.view(-1, self.hidden_size) # h_out을 출력으로 사용한다.
out = self.fc(h_out)
return outCase2)
outputs, hidden = self.lstm(X, hidden_and_cell)
outputs = outputs[-1] # 최종 예측 Hidden Layer
model = torch.mm(outputs, self.W) + self.b # 최종 예측 최종 출력 층
return modellstm_out, self.hidden_cell = self.lstm(input_size=input_seq.view(len(input_seq),1, -1),
hidden_size=self.hidden_cell)
predictions = self.linear(lstm_out.view(len(input_seq), -1))
return predictions[-1]
[완료] Q5. Hidden_layer에서 input_feature로 형 변환 할 시 방법은? (나의 질문) (파이토치 포럼 글 링크)
- 입력은 [batch_size, seq_len, hidden_size] 이거나, [seq_len, batch_size, hidden_size] 가 될수 있는데, 이때 .view()와 .reshape()를 잘못 사용하면 데이터가 틀어질 수 있다.
- 올바른 방법은 .transpose() 혹은 .permute()를 사용하는 것이다.
- .view()와 .reshape()는 텐서를 펴는데(flatten) 사용하지만, 축을 바꿀 때(swapping dimension)는 사용하지 않도록 한다.
#batch_size, seq_len = 3, 5
>>> A
tensor([[1., 1., 1., 1., 1.],
[2., 2., 2., 2., 2.],
[3., 3., 3., 3., 3.]])
A1 = a.transpose(1,0)
A2 = a.permute(1,0)
tensor([[1., 2., 3.],
[1., 2., 3.],
[1., 2., 3.],
[1., 2., 3.],
[1., 2., 3.]])
# 올바르게 축 변환이 되는 모습이다.
A3 = a.view(seq_len, -1)
A4 = a.reshape(seq_len, -1)
tensor([[1., 1., 1.],
[1., 1., 2.],
[2., 2., 2.],
[2., 3., 3.],
[3., 3., 3.]])
# 올바르게 축 변환이 안된다.
1-3) Multivariate time series (anomaly) data using LSTM
discuss.pytorch.org/t/can-lstm-run-multivariate-time-series/93779
www.youtube.com/watch?v=ODEGJ_kh2aA
curiousily.com/posts/time-series-anomaly-detection-using-lstm-autoencoder-with-pytorch-in-python/
-끝-
(이하 정리 안된 참고 자료....)
RNN 학습 시 입력 파라미터
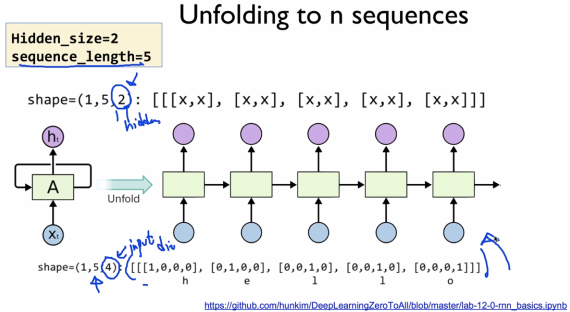
Hidden_size(2)는 사용자 마음대로 정할 수 있다.
Sequence_Length는 5개를 Unfold 한다는 뜻이다.
Hidden State에서도 Sequence_Length(5)를 그대로 사용한다.
LSTM은 sequence를 batch로 처리가능하고, LSTMCell은 sequence의 각 time step 1개씩 처리한다.
LSTMCell을 for loop로 처리하면, LSTM과 같은 효과입니다.
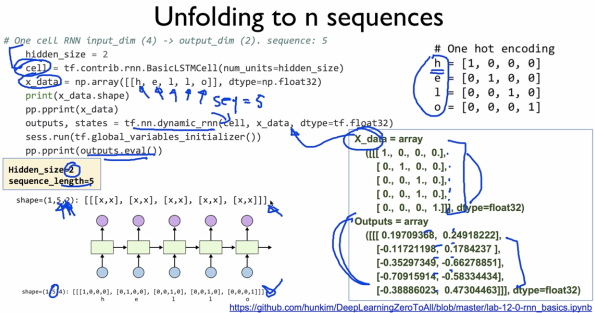
출력은 dimension 2개인 5개의 출력이 나온다.
BatchSize로 줄 경우 (3, 5, 4)
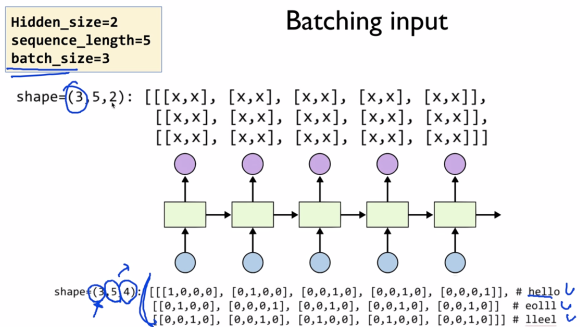

출력은 (3, 5, 2)
pytorch.org/docs/stable/generated/torch.nn.LSTM.html
'데이터 과학 > 딥러닝 FrameWork' 카테고리의 다른 글
| Tensorboard에서 Open3D 사용하기 (0) | 2023.02.19 |
|---|---|
| torch_scatter 설치 (0) | 2022.12.16 |
| 모델 앙상블(ensemble) 하기 (0) | 2021.02.26 |
| Trouble Shooting (0) | 2021.01.31 |
| Torch 데이터셋 & 데이터 로더 + Transforms (0) | 2021.01.30 |


