※ 아래의 글은 Colah의 "Understanding LSTM Network"를 번역한 것입니다.
Contents
1. RNN(Recurrent Neural Network)
2. RNN의 단점
3. LSTM Network
4. LSTM Network 상세
5. 다양한 LSTM Network 종류
6. 다음 방향
7. Pytorch LSTM Network
1. RNN(Recurrent Neural Network)
과거 사건(시간이 지난 사건)을 네트워크에 반영할 수 없는 것은 기존 NN(Neural Network)의 단점이었다.
RNN은 루프(Loop)를 이용하여 이 문제를 해결하였다.

루프는 같은 네트워크를 반복하여 사용하지만(multiple copies of the same network), 정보가 다른 스텝으로 넘어가게 해준다(passing a message to a successor).
[21.04.06 추가] (강의 참고)
위의 RNN 그림을 수식으로 나타내면 아래와 같다.
$ h_t = f_W(h_{t-1}, x_t) $
$ h_t = tanh(W_{hh} * h_{t-1} + W_{xh} * x_t) $
$ y_t = W_{hy}h_t $
즉, RNN은 가중치가 3개($W_{hh}$, $W_{xh}$, $W_{hy}$) 존재한다.
- $ W_{hx}$ : 입력 x에 곱해지는 가중치
- $ W_{hh}$ : 이전 hidden state에 곱해지는 가중치
- $ W_{hy}$ : y 출력 전에 곱해지는 가중치

2. RNN의 단점
가끔은 과거 정보가 많이 필요하지 않는 경우가 있다. 아래 예시의 경우 많은 과거 정보를 필요로 하지 않는다.
“the clouds are in the ___”
공백의 단어는 'sky'일 확률이 높다.

RNN은 이전 정보를 현재 노드에 전달하는데 유용하며 해당 문제를 해결하는데 활용이 가능하다.
하지만, 오래된 과거 정보를 이용하고자 할 경우, 학습이 잘 안되는 단점(long-term dependency problem)이 있다(논문 참조).
“I grew up in France… I speak fluent ___.”
예시에서 한참 전에 이야기한 'France'를 기억하고 있어야 만 공백의 단어가 'French'임을 유추할 수 있다.

이러한 RNN의 단점을 보강한 것이 LSTM이며 이는 Speech recognition, Language modeling, translation, Image captioning 등 다양하게 사용된다.
3. LSTM Network
LSTM은 97년 처음 소개 되었고, 계승 발전되어 왔다(논문 참조).

위의 RNN 모델을 자세히 들여다보면 Concatenate + tanh layer가 들어간다.

반면, LSTM 모델은 다소 복잡하다.

화살표는 벡터를 나타내며, 하나의 출력 노드에서 다른 노드로의 입력을 나타낼 때 쓰인다.
O은 벡터 합이다(Vector Addition)
선 합병은 Concatenate, 선 분기는 같은 정보의 분기를 나타낸다.

위의 부분은 정보가 흘러가는 부분이며, 정보를 수집하는 부분이기도 한다. 정보의 컨베이어 벨트 역할을 한다.
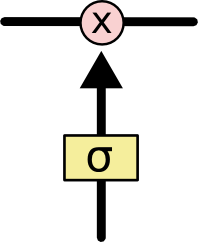
위의 부분은 LSTM의 정보가 컨베이어 벨트에 진입하기 위한 게이트 역할을 하며, Sigmoid와 점곱(Pointwise Multiplication) 연산을 포함한다. Sigmoid 계층은 0~1 값을 가지며 정보를 들여 보낼 것인지, 말 것인지를 결정한다.
4. LSTM Network 상세
Total) Input Gate + Forget Gate + Output Gate

Part1) Forget Gate_1

$f_t$는 $h_{t-1}$과 $x_t$를 본다. "input gate layer"라 불리는 Sigmoid 계층은 어떤 값을 업데이트 할 것인지를 나타낸다.
[21.04.06 추가]
$x_t$ : Current Input data
$h_{t-1}$ : Hidden State, Short-term memory
forget vector($f_t$)는 현재 Input($x_t$)와 Short-term Memory($h_{t-1}$) 곱으로 생성된다.
Part2) Input Gate

tanh 계층은 $\tilde{C_t}$ 라는 새로운 후보 값을 가지는 벡터 값을 생성한다. 이 값은 상태(State)에 추가할 수 있다.
다음 스텝으로 이 둘을 결합하여 상태를 업데이트한다.
언어 모델의 예에서는 새 주어의 성별을 셀 상태에 추가하여 잊어버린 이전 주어를 대체하려고 한다
(해당 말이 무슨 말인지는 정확히 이해하지 못했다.)
※ $\tilde{C_t}$로 표현한 것은 정보의 컨베이어 벨트를 따라 흐르는 $C_t$에 더하기 위한 후보라는 의미에서 물결을 붙인 것 같다.
[21.04.06] 추가설명
Input Gate는 새로운 정보($x_t$)중 어떤 것을 Long-term Memory에 저장할 것인지 결정한다.
현재 Input($x_t$)와 Short-term Memory($h_{t-1}$)로 결정한다. 필터 역할을 한다.
Part3) Forget Gate_2

이전 상태 $C_{t-1}$를 업데이트하여 새로운 셀 상태인 $C_t$로 바꿀 차례이다.
$C_{t-1}$을 $f_t$와 점곱한다. 그리고 $i_t *\tilde{C_t}$를 점덧셈(Pointwise Addition)한다. 따라서 새로운 셀 후보값을 만들어 낸다.
해당 부분은 (언어 모델의 경우), 이전 주어의 성별에 대한 정보를 삭제하고 새 정보를 추가하는곳이다.
(이부분도 무슨 말인지 정확히 이해하지 못했다.)
[21.04.06] 추가설명
$C_{t-1}$ : Cell State, Long-term Momory
$C_{t}$ : New Cell State
Long-term Memory중 어떤 정보를 유지하고(keep) 버릴지(discard) 결정한다. Long-term Memory($C_{t-1}$)에 forget vector($f_t$)를 곱한다. 그리고 새로운 셀 후보값($i_t *\tilde{C_t}$) 을 더한다.
"무언가를 잊고, 새로운 기억을 더한다"
Part4) Output Gate
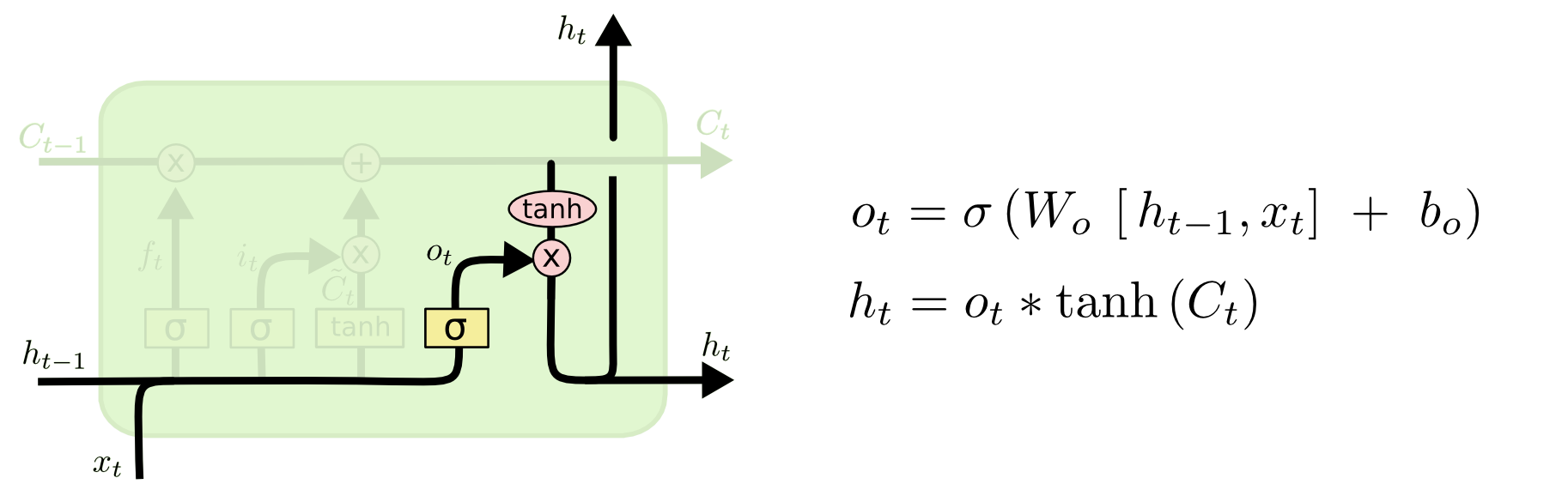
이제 출력을 결정할 차례이다. 첫째로 어떤 부분의 셀 상태를 출력을 내보낼 것인지를 결정하는 Sigmoid 계층을 실행한다. 다음, 셀 상태($C_t$)를 tanh에 통과 시킨다(-1 ~ 1)의 값을 가지게 된다. 그리고 Sigmoid 계층을 통과한 것과 점곱을 한다.
언어모델을 예로 들면, 주어(Subject)를 보고, 동사에게 관련된 정보를 주려는 것과 같다. 즉, 주어가 단수(Single)인지 복수(Plural)인지를 보고, 어떤 형태의 동사를 (문법상)내보낼 것인지를 판단하는 것이다.
즉, 복수형 동사가 올건지, 3인칭 단수 동사가 올것인지를 결정하게 된다.
[21.04.06] 추가설명
$h_{t}$ : New Hidden State
전체를 코드로 정리하면 다음과 같다.
# Middle Layer
ft = sigmoid(np.dot(xt, Wf) + np.dot(ht_1, Uf) + bf) # forget gate
it = sigmoid(np.dot(xt, Wi) + np.dot(ht_1, Ui) + bi) # input gate
ot = sigmoid(np.dot(xt, Wo) + np.dot(ht_1, Uo) + bo) # output gate
# Output Layer
Ct = ft * Ct_1 + it * np.tanh(np.dot(xt, Wc) + np.dot(ht_1, Uc) + bc)
ht = ot * np.tanh(Ct)5. 다양한 LSTM Network 종류
Original)

변형1)

gate layer로 하여금 셀상태($C_t$)를 보게하는 LSTM 변형 네트워크이다.
변형2)
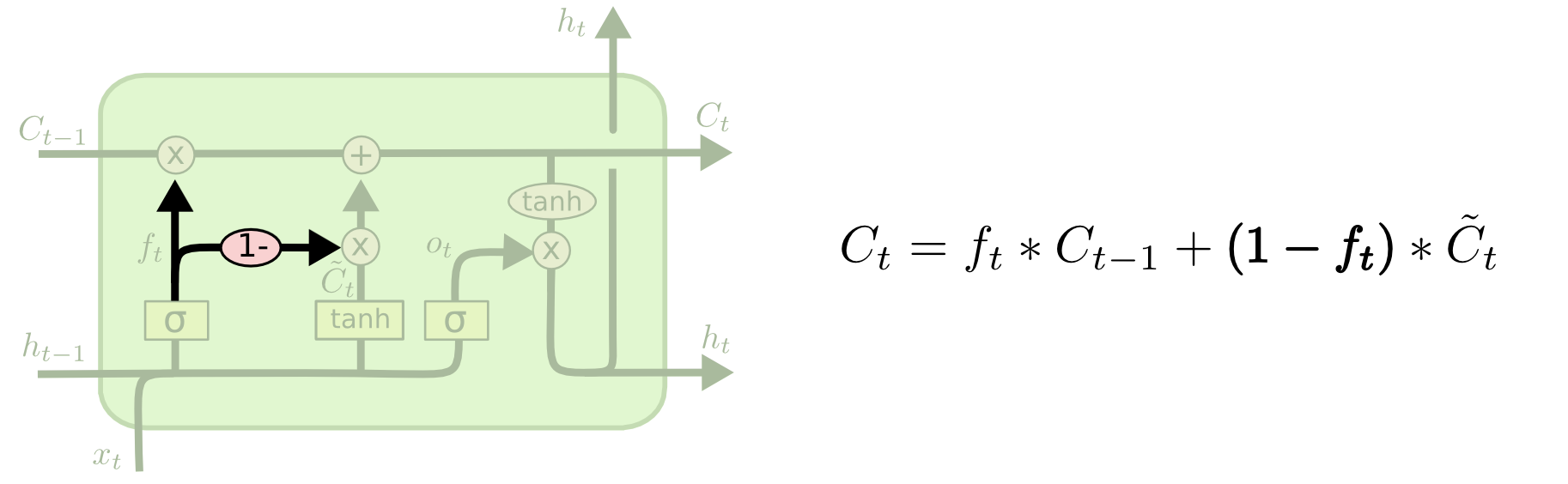
다른 변형은 결합된(coupled) forget(?)과 입력 게이트를 사용하는 것이다. 무엇을 잊고, 무엇에 새로운 정보를 추가해야하는지 결정하는 대신, 이러한 결정을 함께 내린다(make those decision together).
We only forget when we’re going to input something in its place. We only input new values to the state when we forget something older(그 자리에 무언가를 입력할 때만 잊어 버린다. 오래된 것을 잊었을 때만, 새로운 값을 상태에 입력한다) (정확히 무슨 뜻인지 이해 되지 않아 원문 그대로 옮겨 놓았다)
변형3)

Forget과 입력 게이트를 하나의 "Update gate"로 결합하였다. 또한, 셀 상태와 숨김 상태를 병합하여 다른 변화를 만들어 낸다.
6. 다음 방향
다음 단계로 나아가는 방향은 Attention 모델이다. 아이디어는 RNN의 모든 단계에서 '더 큰 정보 모음'에서 볼 정보를 선택하게 하는 것이다(let every step of an RNN pick information to look at from some larger collection of information)
예를 들어, 이미지 캡쳐를 묘사하는데 RNN을 사용하고자 한다면, 이미지 부분을 선택하여 출력하는 모든 단어를 볼 수 있다.
7. Pytorch 모델
class torch.nn.LSTMCell(input_size: int, hidden_size: int, bias: bool = True)
'''
input_size : 입력 x의 feature 수
hidden_size : hidden state h의 feature 수
bias : False일 경우 편항 b_ih와 b_hh를 가지지 않는다.
'''
<다른 관점에서 설명한 내용(밑바닥 딥러닝2)>
1. RNN(Recurrent Neural Network)

$ tanh(h_{t-1}W_{h} + x_{t}W_{x} + b) $

2. RNN의 단점


위의 문장에서 [?]에 들어갈 단어를 찾기 위해 학습 한다고 생각해보자. 기존의 RNNLM 학습 관점에서, 시간이 지난 과거를 기억하기 위해서는 과거 방향으로 '의미 있는 기울기'를 전달함으로써 시간에 Dependent한 내용을 학습할 수 잇지만, 대부분 시간이 지날 수록(시간이 지난 내용일 수록) 기울기가 작아지거나, 커진다.
2.1 RNN에서 과거 사건의 기울기가 소멸하는 이유1 - tanh

tanh의 미분 곡선을 보면, 값이 통과 될수록 값이 작아지게 된다(출력 y값을 다시 입력 x값으로 넣으면 작아지는 것을 확인할 수 있다)
2.2 RNN에서 과거 사건의 기울기가 소멸하는 이유2 - $W_h$

import numpy as np
import matplotlib.pyplot as plt
N = 2
H = 3
T = 20 # 시계열 데이터의 길리
dh = np.ones((N, H))
np.random.seed(3)
Wh = np.random.rand(H, H) # 기울기 폭발
#Wh = np.random.rand(H, H) * 0.5 # 기울기 소실
norm_list = []
for t in range(T):
dh = np.matmul(dh, Wh.T)
norm = np.sqrt(np.sum(dh**2)) / N
norm_list.append(norm)
plt.plot(norm_list)
plt.show()
(참고 : Vanishing/Exploding Gradients (C2W1L10))
(On the difficulty of training Recurrent Neural Networks)
2.3 RNN의 기울기 문제를 해결하기 위한 방법
- Gradient Clipping : 모든 매개 변수의 기울기를 모아($\hat{g}$), 문턱 값을 초과할 경우 기울기 수정하는 방법
def clip_grads(grads, max_norm):
total_norm = 0
for grad in grads:
total_norm += np.sum(grad ** 2)
total_norm = np.sqrt(total_norm) # L2 정규화, ||\hat{g}||
rate = max_norm / (total_norm + 1e-6)
if rate < 1:
for grad in grads: # grad == \hat{g}
grad *= rate
3. LSTM Network
- LSTM은 RNN과 다르게 C라는 경로가 존제하며 기억 셀(memory cell) 이라고도 부른다.
- 기억 셀 C는 LSTM 내에서만 정보를 주고 받고, 외부 네트워크에 노출되지 않는 특징이 있다.
본인의 질문
Q. 2.1에서 tanh를 지난다고, 기울기가 감소한다고 할수 있을까?
예를 들어 x=0.5라고 해보면, y값 (눈대중으로) 0.8이 나온다. 다시 x=0.8을 넣으면, (눈대중으로) y=0.4가 나온다. 여기서는 수축하는 것으로 보이지만, 다시 x=0.4를 넣으면, (눈대중으로) 0.8 ~ 0.9 값이 나와서 되려 증가하게 된다. 어떻게 tanh가 기울기가 소실되는 문제가 있다고 할수 있을까?
A. (여기에 대해선 아직 답을 못구했다)
[Reference]
[1] 밑바닥 부터 시작하는 딥러닝2
[2] Neural networks and deep learning by Aurélien Géron, 2018
[3] pytorch.org/docs/stable/generated/torch.nn.LSTMCell.html
'데이터 과학 > 딥러닝(Deep Learning)' 카테고리의 다른 글
| PCA(주성분 분석) 정리 (0) | 2021.02.10 |
|---|---|
| Autoencoder 설명 (0) | 2021.02.06 |
| Sigmoid 함수 vs Softmax 함수 (0) | 2021.02.01 |
| Transformer 설명 (0) | 2021.01.14 |
| Attention 모델 - 구현편 (0) | 2020.12.27 |



