서론
- 완전 지도 학습을 위한 라이다 포인트 클라우드 라벨링은 비용이 많이 든다.
- 본 논문은 Semi-Supervised Learning 기반 Lidar Segmentation 방법을 연구하였다.
- 핵심 아이디어는 LiDAR 포인트 클라우드의 강력한 공간 단서(Strong Spatial Cues)를 활용하여 레이블이 없는 데이터를 더 잘 활용하는 것
- 다양한 Lidar 스캔의 레이저 빔(Laser Beams)을 혼합하여, 일관되고 확실한 예측을 할 수 있도록 LaserMix를 제안한다.
- 본 모델은 3가지 특성이 존재한다.
1) 일반화(Generic)
: LaserMix는 LiDAR 표현(e.g. 거리 범위 및 복셀)에 구애받지 않으므로 SSL 프레임워크를 보편적으로 적용할 수 있다 ==> 보편적인 적용 가능
2) 통계적 근거(Statistically grounded)
: 제안된 프레임워크의 적용 가능성을 이론적으로 설명하기 위한 상세한 분석을 제공
3) 효율성(Effective)
: 널리 사용되는 LiDAR Segmentation 데이터 세트(nuScenes, SemanticKITTI 및 ScribbleKITTI)에 대한 포괄적인 실험 분석은 본 논문의 효과성과 우수성을 입증함
- 본 논문은, 2배에서 5배 더 적은 레이블로 완전 감독 대상에 비해 경쟁력 있는 결과를 달성하였고, 감독 학습 대비 평균 10.8% 성능 향상 시켰다.
개요

(a) LiDAR 스캔에는 강력한 공간 사전 지식이 포함되어 있다. 자가 차량 주변의 물체와 배경은 다양한 레이저 빔에 패턴화된 분포를 가지고 있습니다.
(b) 장면 구조에 따라 제안된 LaserMix는 다양한 LiDAR 스캔의 빔을 혼합합니다. 이는 범위 뷰 및 복셀 표현과 같은 널리 사용되는 다양한 LiDAR 표현과 호환된다.
(c) LaserMix는 NuScene의 낮은 데이터(10%, 20% 및 50% 라벨) 및 높은 데이터(전체 라벨) 체제 모두에서 SOTA 방법보다 우수한 결과를 달성한다.
하이라이트
SSL에 대한 공간 사전 지식 활용(Leveraging the Spatial Prior for SSL)
- Fig 1 (a)에서 나타난 것과 같이 실제 물체/배경의 분포는 LiDAR 스캔의 공간 위치와 강한 상관관계가 있습니다.
- 포인트 클라우드의 특정 공간 영역 내의 객체와 배경은 유사항 패턴을 따릅니다.
예를 들어, 근거리 영역은 도로일 가능성이 높고, 원거리 영역은 빌딩과 초목일 가능성이 높습니다.
==> 저자의 해당 주장에 대해서 공감한다. 하지만, 주행 환경에 따라 사물 분포가 다를 것 같다.
- 즉, 공간 영역이 존재하는데 해당 영역a (∈A)에서는 라이다 포인트와 라벨이(Xin, Yin) 낮은 변동성을 가진다.
- 공식으로 표현하면 조건부 엔트로피 H(Xin, Yin | A)는 작다.
- 본 논문은 세그멘테이션 모델이 미리 정의된 영역(Predefined Area)에서 확실하고 일관성 있는 예측을 하는 방법을 제안한다.
- 미리 정의된 영역 A는 사전지식 강도(Strength)를 결정한다.
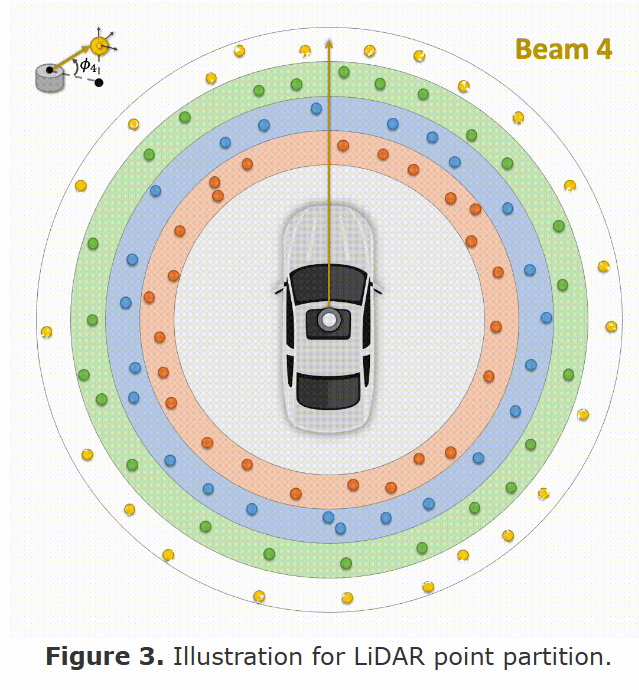
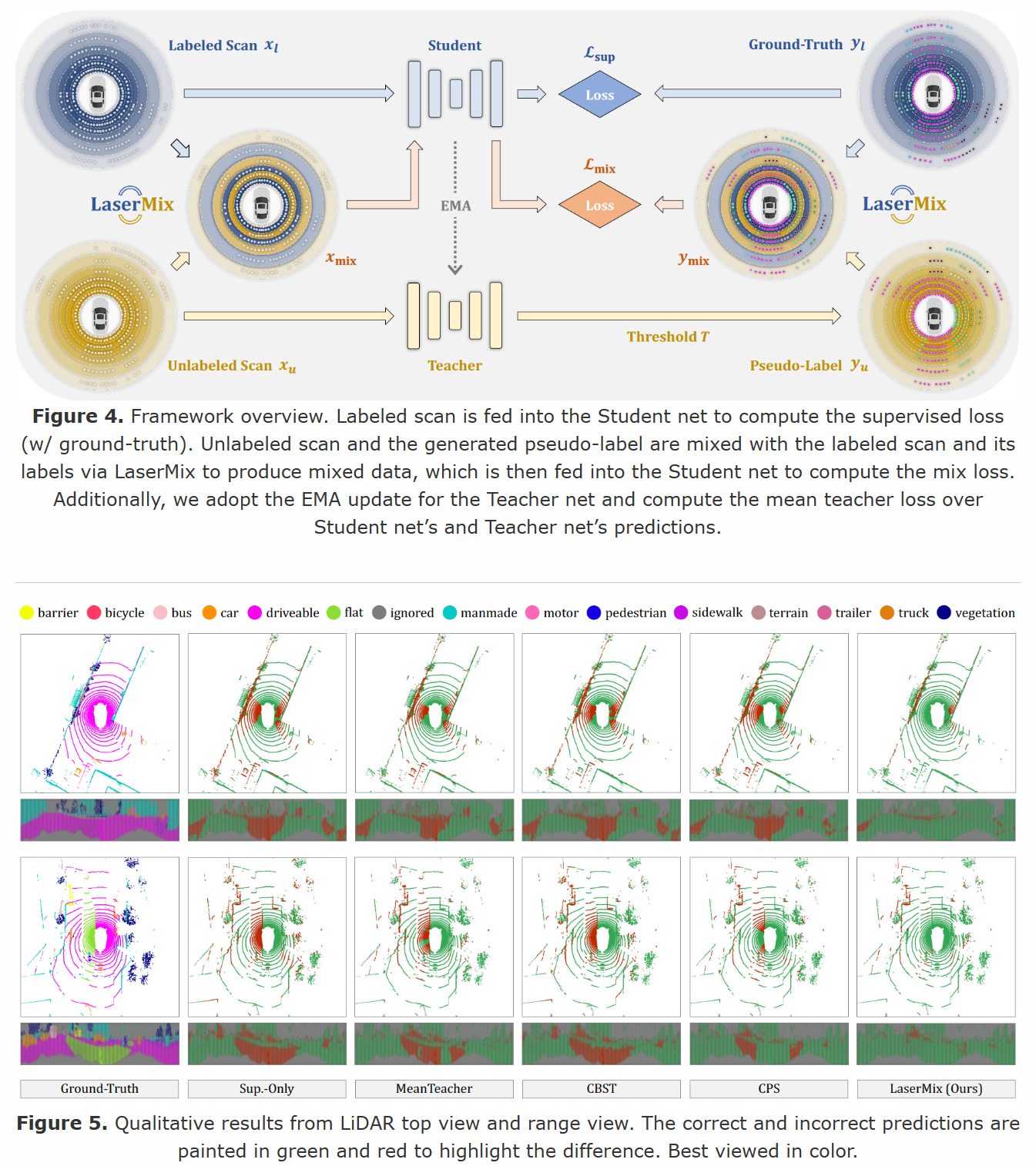
Laser Beam Partition & Mixing
'논문 리뷰(Paper Review)' 카테고리의 다른 글
| BEVFusion: Multi-Task Multi-Sensor Fusionwith Unified Bird’s-Eye View Representation, IRCA2023 (0) | 2023.09.24 |
|---|---|
| Voxel Transformer, ICCV2021 (0) | 2023.09.06 |
| Spherical Transformer for LiDAR-based 3D Recognition (0) | 2023.08.29 |
| Scribble-Supervised LiDAR Semantic Segmentation (0) | 2023.07.27 |
| CVPR2023 참관 후기 (0) | 2023.06.24 |



