※ 아래 글은 https://machinelearningmastery.com/lstm-autoencoders/ 해당 링크를 요약한 것입니다.
<Contents>
Introduction
Encoder-Decoder LSTM Models
Early Application of LSTM Autoencoder
Code
Introduction
- LSTM Autoencoder는 Encoder-Decoder LSTM 구조를 사용하는 Sequence 데이터를 위한 Autoencoder로 볼 수 있다(Learn compressed representation of sequence data, e.g. video, text, audio and time series sequence date)
- 학습시에 Encoder 부분은 Sequence 데이터를 Encoder 하여 특징 벡터를 만들어 낸다. 병목 지점에서 모델의 출력은 입력 데이터의 압축된 표현을 나타내는 고정 길이 벡터이다.
- seq2seq 등 시간 순서를 입력으로 받는 모델들이 존재한다.
※ 참고로, 연속적인 데이터는 일반적으로 지도학습(Supervised-Learning) 모델의 입력으로 넣기 위한 특징 추출을 하기가 어렵다. 도메인 지식, 신호처리 지식을 심화적으로 필요로 한다.
Encoder-Decoder LSTM Models
- LSTM 모델은 Encoder-Decoder LSTM로 구성될 수 있는데, 가변 길이 입력 순서를 지원하고, 가변 길이 출력을 지원한다.
- Encoder-LSTM은 입력 순서를 step-by-step으로 읽고, Hidden state 혹은 Output은 내부 학습된 표현을 고정된 길이의 Vector로 표현한다.
- 벡터는 Decoder의 입력으로 들어가서 각 step 마다 해석한다.
- 학습 후에 모델이 원하는 수준의 Sequence 데이터를 생성하게 된다면, Decoder 부분이 제거되고 Encoder 부분만 남게 된다.
- 해당 모델의 사용하여 입력 순서(Input Sequnce)를 고정된 사이즈의 벡터로 Encode 할 수 있게 되는 것이다.
- LSTM Autoencoder는 2015년 논문에서 처음 제안되었다.
Early Application of LSTM Autoencoder
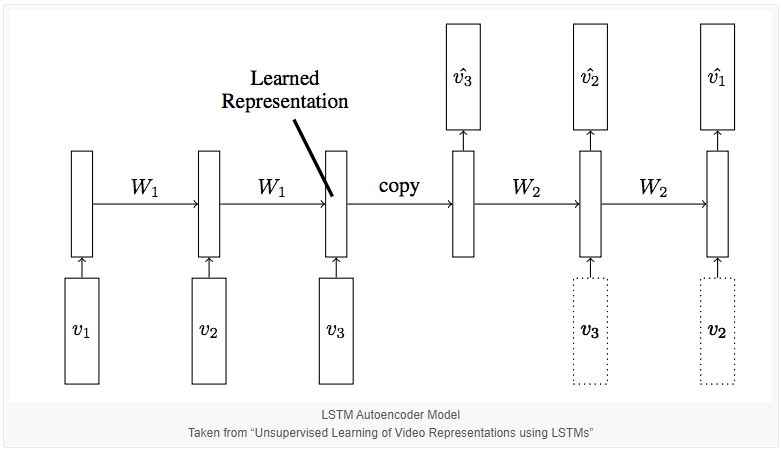
[논문 中 이해가 되지 않는 부분]
"The target sequence is same as the input sequence, but in reverse order. Reversing the target sequence makes the optimization easier because the model can get off the ground by looking at low range correlations."
--> 타겟이 되는 순서는 입력 데이터의 순서와 동일하지만 역순이다(?). 타겟 순서(출력하고자 하는 결과물 순서를 말하는 가??)를 반대로 하면, 모델이 Gound를 제거할 수 있고(무슨말?) 낮은 범위의(?) 상관관계를 살펴봄으로써 최적화가 더 쉬워진다(?)
--> 논문에서는 Decoder는 Conditional or Unconditioned 두가지 버전이 가능하다는 내용도 나온다.
※ 어떤 사람이 위의 논문을 Pytorch로 구현한 것을 보았는데, 성능이 매우 떨어지는 것 같았다.
- 더욱 정교한 모델은 두개의 Decoder를 사용하는 것이다. 하나가 다른 하나를 위해 사용된다.
- 하나는 다음 프레임을 예측하기 위해, 다른 하나는 합성 모델(Composite Model)이라 하는 시퀀스 프레임을 재구성(Reconstruct) 한다.
- Reconstruction은 입력 프레임 순서의 역순이다.

- LSTM Encoder로 부터 학습한 가중치를 이용해서 LSTM 분류기를 초기화 하였다.
- 실험상에서 Decoder에 조건을 추가하지 않은 합성(Composite) 모델이 성능이 가장 좋았다.
- 가장 성능이 좋은 모델은 Autoencoder와 Future Predictor를 결합한 모델이었다.
Code
Reconstruction LSTM Autoencoder
# define model
model = Sequential()
model.add(LSTM(100, activation='relu', input_shape=(n_in,1)))
model.add(RepeatVector(n_in))
model.add(LSTM(100, activation='relu', return_sequences=True))
model.add(TimeDistributed(Dense(1)))
model.compile(optimizer='adam', loss='mse')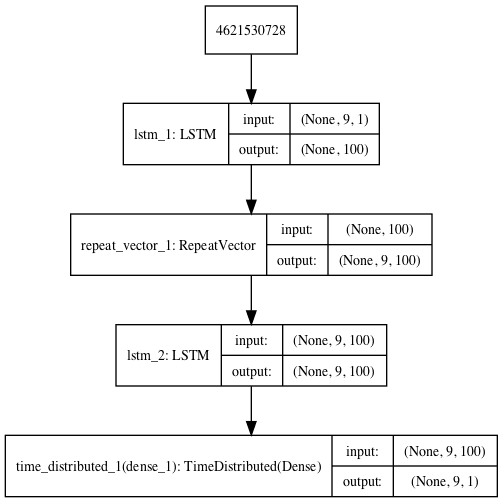
Prediction LSTM Autoencoder
# define model
model = Sequential()
model.add(LSTM(100, activation='relu', input_shape=(n_in,1)))
model.add(RepeatVector(n_out))
model.add(LSTM(100, activation='relu', return_sequences=True))
model.add(TimeDistributed(Dense(1)))
model.compile(optimizer='adam', loss='mse')
plot_model(model, show_shapes=True, to_file='predict_lstm_autoencoder.png')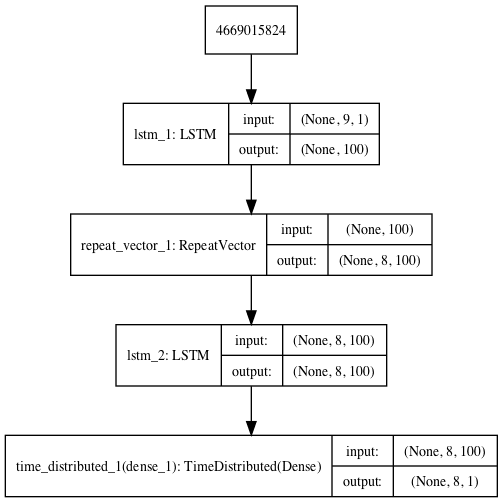
Composite LSTM Autoencoder
- Single encoder & two decoder
# define encoder
visible = Input(shape=(n_in,1))
encoder = LSTM(100, activation='relu')(visible)
# define reconstruct decoder
decoder1 = RepeatVector(n_in)(encoder)
decoder1 = LSTM(100, activation='relu', return_sequences=True)(decoder1)
decoder1 = TimeDistributed(Dense(1))(decoder1)
# define predict decoder
decoder2 = RepeatVector(n_out)(encoder)
decoder2 = LSTM(100, activation='relu', return_sequences=True)(decoder2)
decoder2 = TimeDistributed(Dense(1))(decoder2)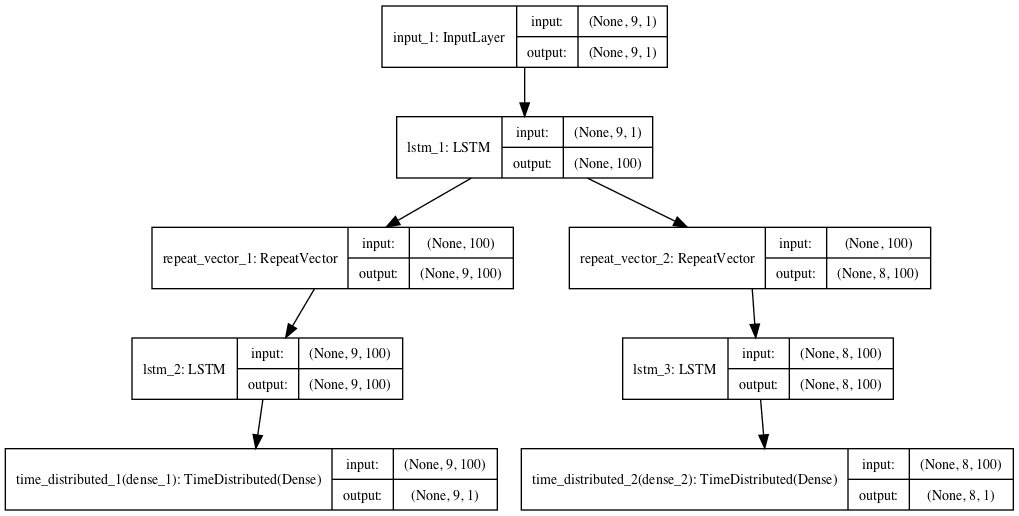
- 어떤 모델을 사용하든, 추론시에는 Encoder만 남아서 고정된 사이즈의 Encoded된 Vector를 생성하게 된다.
- 기존 모델과 동일한 입력을 받고, (Repeated Vector 레이어 이전에) Encoder 모델 끝 부분에서 출력을 내는 새 모델을 생성하여 수행 가능하다(쉽게 말해 Encoder 부분만으로 Model을 새로 구성하는 방법이다)
# connect the encoder LSTM as the output layer
model = Model(inputs=model.inputs, outputs=model.layers[0].output)
개인적으로 궁금한 부분
LSTM vs LSTM-Autoencoder 성능차이?
LSTM Anormaly detection vs LSTM-Autoencoder Anormaly detection 성능차이?
참고)
개념
https://machinelearningmastery.com/lstm-autoencoders/
https://machinelearningmastery.com/encoder-decoder-long-short-term-memory-networks/
구현
'데이터 과학 > 딥러닝(Deep Learning)' 카테고리의 다른 글
| Triplet Loss 구현 (0) | 2022.06.09 |
|---|---|
| CenterLoss의 구현 (0) | 2022.05.30 |
| 공분산(Covariance) 정리 (0) | 2021.02.12 |
| PCA(주성분 분석) 정리 (0) | 2021.02.10 |
| Autoencoder 설명 (0) | 2021.02.06 |



