<목차>
- 서론 (모델 양자화의 필요성)
- 일반적인 ML 데이터 타입
- 모델 양자화 소개
- 적용 관점 (허깅페이스로의 통합)
- 적용 관점(accelerate 사용)
서론 (모델 양자화의 필요성)

- 예시로, BLOOM-176B를 학습하기 위해서는 8x 80GB A100 GPUs (~$15k each)가 필요하며
- 이를 미세조정하려면 72 GPUs가 필요합니다.
- 적은 GPU로 성능을 유지하면서 모델을 실행시킬 양자화 증류 기법이 존재합니다.
- Int8 추론 연구는 메모리를 2배 감소하면서 성능을 유지하며, 이는 Hugging Face Transformers에 통합되었습니다.
i.e. LLM.int8() 은 모든 허깅페이스 트랜스포머 모델에 통합되었다.
(자세한 사항은 아래 논문 참조)
[2208.07339] LLM.int8(): 8-bit Matrix Multiplication for Transformers at Scale (arxiv.org)
아래 내용에서는 전반적인 양자화 기술을 살펴보고 LLM에서 어떠한 것이 메모리를 크게 차지하는지 살펴봅니다.
추가 설명)
- bitsandbytes는 University of Washington의 박사과정 Tim Dettmers가 Facebook AI Research(現 Meta AI)와 함께한 연구인 LLM.int8()를 오픈 소스로 공개한 것
- Hugging Face의 Transformer 구현체에도 병합이 되었으며, Llama2, QLoRA, KoAlpaca, 그리고 KULLM 등의 다양한 모델에서 사용되고 있습니다.
일반적인 ML 데이터 타입
- 모델 파라미터는 아래와 같이 타입을 조정함으로써 사이즈를 줄일 수 있습니다.
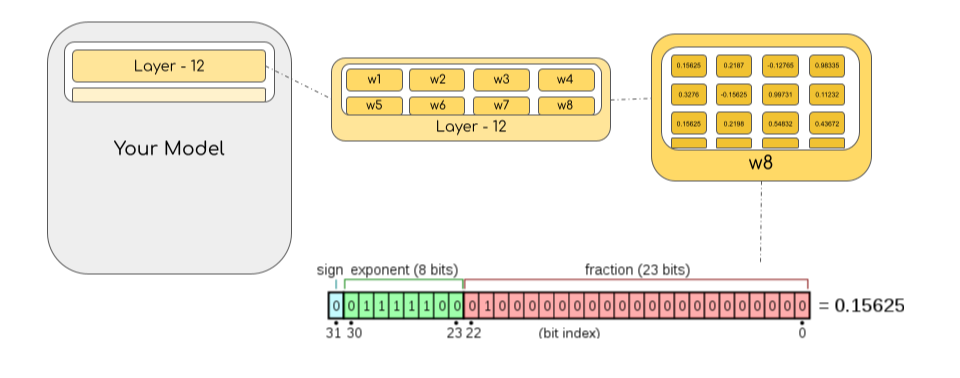
- 대부분의 HW는 FP32를 지원하며 (1bit 부호, 8 bits exponent, 23 bits mantissa) 정보를 담습니다. IEEE 32bit 표준
- FP16에서는 (1bit 부호, 5 bits exponent, 10 bits mantissa) 정보를 담습니다.
(FP16은 매우 큰수에 Overflow, 매우 작은 수에 Underflow 할 가능성이 있다)
(최대 표현 수는 64,000이므로 그 이상 수는 NaN으로 표기됩니다. 신경망에서 한번 NaN로 계산되면 그 이후 계산은 모두 망가집니다)
(이러한 문제를 해결하기 위해 Loss Scaling 방법이 있지만 항상 동작하는 것은 아닙니다)
참조: CUDA Automatic Mixed Precision examples — PyTorch 2.2 documentation
==> 파라미터와 로스의 데이터 표현 방식은 민감하고 어려운 주제이다.
- BFLOAT16은 FP32과 동일한 지수 부를 가지면서 가수부를 7bits로 만든 것입니다. 이는 곳 가수부의 3bit 손실을 의미한다. 즉, FP32 처럼 큰수를 표현할 수 있으면서 정확도는 조금 포기하는 것입니다.
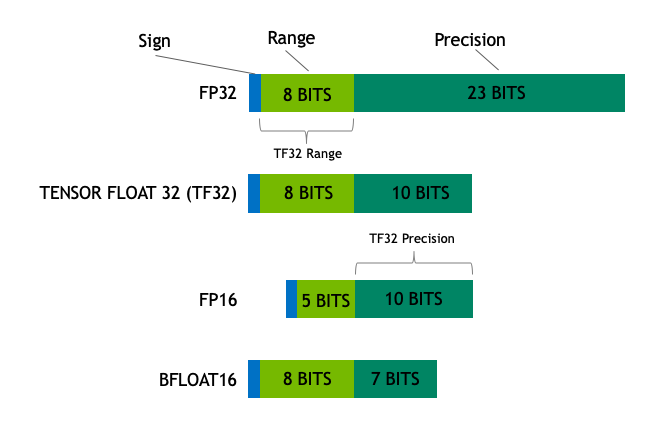
- NVIDIA는 BF16 <-> FP16을 동적으로 정하는 TF32 포맷을 소개 했습니다 (특정 연산일 때 내부적으로 사용된다)
- 일반적으로 FP32는 4바이트 정확도, BF16/FP16은 2바이트 정확도를 가진다고 얘기합니다.
- 또한 int8(INT8) 데이터 유형은 2^8개의 서로 다른 값(부호 있는 정수의 경우 [0, 255] 또는 [-128, 127] 사이)을 저장할 수 있는 8비트 표현으로 구성됩니다.
- 이상적으로 학습과 추론은 FP32로 이뤄져야 합니다. 이는 FP16/BF16 보다 2배 느립니다. 따라서, 위에서 언급한 Mixed Precision 접근법이 사용되어 가중치는 32bits로 저장하되, 순전파/역전파에서는 FP16/BF16으로 수행하여 학습 속도를 높입니다. 역전파 시에 계산된 FP16/BF16 기울기는 FP32 포맷 가중치를 업데이트 합니다.
==> 경험상 Mixed Precision을 사용하면 배치는 1.5배 이상 늘었고, 학습 속도도 빨랐다.
- 학습하는 동안 주요 가중치는 FP32로 저장되나 실전에서는 Half-Precision(2바이트 정확도) 가중치도 유사 정확도를 보입니다. (다수의 가중치 업데이트를 수행할 때만 Full-Precision이 필요하다??)
- 이는 곳 GPU의 절반만 사용해서 유사 성능을 낼 수 있다는 뜻이 됩니다.
사이즈 계산법 예시) BLOOM-176B, FP16/BF16은 176 * 10^9(Billion) * 2bytes = 352GB 사이즈가 된다.
모델 양자화 소개
- 위에서 소개한 FP16 / BF16은 학습 속도와 메모리 감소를 가지지만, 추론 성능이 떨어질 수 있습니다.
- 양자화는 데이터를 "rounding, 반올림" 하는 것입니다. 만약 0~9 범위를 가지는 숫자를 0~4 범위 숫자를 가지는 타입으로 바꾸면, 4->2가 되고 3->2(1을 반올림하여 2) 이 됩니다. 따라서, 4, 3 값을 2로 통일하였으니 이는 정보의 손실이 필연적입니다.
- 가장 일반적인 8비트 양자화 기술 두 가지는 0점 양자화와 절대 최대(absmax) 양자화입니다. 0점 양자화 및 absmax 양자화는 부동 소수점 값을 보다 컴팩트한 int8(1바이트) 값으로 매핑합니다. 첫째, 이러한 방법은 입력을 양자화 상수로 스케일링하여 입력을 정규화합니다.
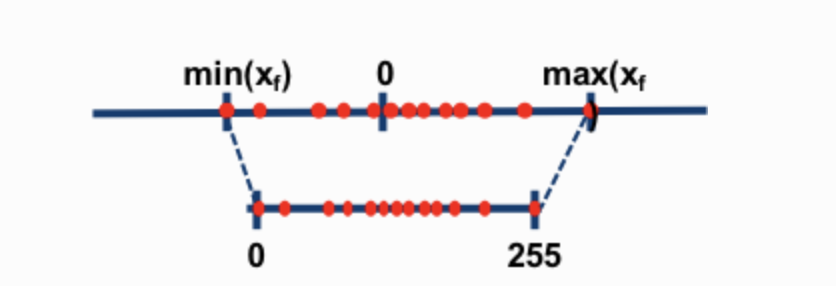
- 0점 양자화에서는 값의 범위가 -1 ~ 1일 경우 이를 -127 ~ 127로 양자화 합니다.
- 127배로 크기를 조정한 다음 이를 8비트 정밀도로 반올림하고 싶습니다( x 127 수행)
- 원래 값으로 되돌아 오려면 int8 값을 동일한 양자화 인자 127로 나누어야 합니다.
- 예를 들어 값 0.3은 0.3*127 = 38.1로 조정됩니다. 반올림을 통해 값 38을 얻습니다. 이를 반대로 하면 38/127=0.2992를 얻습니다. 이 예에서는 양자화 오류가 0.008입니다.
- 이렇게 사소해 보이는 오류는 모델 레이어를 통해 전파되면서 누적되고 커지는 경향이 있으며 결과적으로 성능이 저하됩니다.
- 절대 최대(absmax) 양자화에서는 FP16 / BF16 숫자와 해당 int8 숫자 사이의 매핑을 계산하려면 먼저 텐서의 절대 최대값으로 나눈 다음 데이터 유형의 전체 범위를 곱해야 합니다.
- 예를 들어, [1.2, -0.5, -4.3, 1.2, -3.1, 0.8, 2.4, 5.4]를 포함하는 벡터에 절대최대 양자화를 적용한다고 가정해 보겠습니다. 이 경우 절대 최대값인 5.4를 추출합니다. Int8의 범위는 [-127, 127]이므로 127을 5.4로 나누고 배율 인수로 23.5를 얻습니다. (127을 텐서의 가장 큰 값으로 나눈 값 알파를 얻는다)
- 따라서 원래 벡터에 이를 곱하면 양자화된 벡터 [28, -12, -101, 28, -73, 19, 56, 127]가 생성됩니다.
(텐서 값을 알파 값으로 스케일링한다, 당연 텐서의 가장 큰 값은 127이 된다.)

- 최신 값을 검색하려면 int8 전체 정밀도 숫자를 양자화 인자(알파)로 나눌 수 있지만 위의 결과는 "반올림"되므로 일부 정밀도가 손실됩니다.
==> FP16 벡터 중 가장 큰 값을 127을 나눈 값 알파를 구한뒤 전체 벡터에 곱해주면, 벡터 전체 값은 -127 ~ 127 값의 범위를 가지게 된다.
- unsigned int8의 경우 최소값을 빼고 절대 최대값으로 크기를 조정합니다.(이렇게 되면 양자화 할 경우 0 ~ 127 값을 가진다) 이는 영점 양자화가 수행하는 작업에 가깝습니다. 이는 최소-최대 스케일링과 유사하지만 후자는 값 "0"이 항상 양자화 오류 없이 정수로 표시되는 방식으로 값 스케일을 유지합니다(이는 장점이다??)
- 이러한 트릭은 보다 정확한 결과를 위한 행렬 곱셈과 관련하여 행별 또는 벡터별 양자화와 같은 여러 가지 방법으로 결합될 수 있습니다. 행렬 곱셈 A*B=C를 살펴보면, 텐서당 절대 최대값으로 정규화하는 일반 양자화가 아닌 벡터 방식 양자화는 A의 각 행과 B의 각 열의 절대 최대값을 찾습니다. 그런 다음 이 벡터를 나누어 A와 B를 정규화합니다.
==> 행별 수행할 수도 있고, 벡터별로(각 행과 각 열에 최대 값을 찾아서) 수행할 수도 있다.
- 그런 다음 A*B를 곱하여 C를 얻습니다. 마지막으로 FP16 값을 얻기 위해 A와 B의 절대 최대 벡터의 외부 곱을 계산하여 비정규화합니다. 이 기술에 대한 자세한 내용은 LLM.int8( ) 논문이나 Tim 블로그의 양자화 및 새로운 기능에 대한 블로그 게시물을 참조하세요.
(상세한 사항은 아래를 참조합니다)
[2208.07339] LLM.int8(): 8-bit Matrix Multiplication for Transformers at Scale (arxiv.org)
LLM.int8() and Emergent Features — Tim Dettmers
결론
- LLM.int8() 테크닉은 HuggingFace Transformer과 Accelerate 라이브러리에 통합되었고, BLOOM-176B과 같은 큰 모델에서도 성능 감소가 없었다.
(일부 생략)
적용 관점 (허깅페이스 통합)
- 위에서 설명한 기능은 bitsandbytes.Linear8bitLt 라이브러리에서 수행이 가능하다.
- 이는 클래식 torch.nn 모듈에서 파생되었으며 아래 설명된 코드를 사용하여 아키텍처에서 쉽게 사용하고 배포할 수 있습니다.
- 다음 사용 사례의 단계별 예는 다음과 같습니다. bitandbytes를 사용하여 int8의 작은 모델을 변환한다고 가정해 보겠습니다.
- 그런 다음 자신만의 모델을 정의할 수 있습니다. 모든 정밀도의 체크포인트나 모델을 8비트(FP16, BF16 또는 FP32)로 변환할 수 있지만 현재 Int8 모듈이 작동하려면 모델 입력이 FP16이어야 합니다. 따라서 여기서는 모델을 fp16 모델로 취급합니다( Int8로 양자화 되지만, 모델은 FP16/BF16 이어야 한다.)
import torch
import torch.nn as nn
#import bitsandbytes as bnb
import bitsandbytes as bnb
from bnb.nn import Linear8bitLt
from bitsandbytes.nn import Linear8bitLt
# https://blog.csdn.net/dandandancpop/article/details/135290871
fp16_model = nn.Sequential(
nn.Linear(64, 64),
nn.Linear(64, 64)
)
# (모델 학습)
torch.save(fp16_model.state_dict(), "model.pt")
int8_model = nn.Sequential(
Linear8bitLt(64, 64, has_fp16_weights=False),
Linear8bitLt(64, 64, has_fp16_weights=False)
)
# has_fp16_weights=True가 되면 Int8로 양자화 되지 않고, 8/16bit Mixed 하게 된다.
int8_model.load_state_dict(torch.load("model.pt"))
print('Before:', int8_model[0].weight)
"""
tensor([[ 0.0031, -0.0438, 0.0494, ..., -0.0046, -0.0410, 0.0436],
[-0.1013, 0.0394, 0.0787, ..., 0.0986, 0.0595, 0.0162],
[-0.0859, -0.1227, -0.1209, ..., 0.1158, 0.0186, -0.0530],
...,
[ 0.0804, 0.0725, 0.0638, ..., -0.0487, -0.0524, -0.1076],
[-0.0200, -0.0406, 0.0663, ..., 0.0123, 0.0551, -0.0121],
[-0.0041, 0.0865, -0.0013, ..., -0.0427, -0.0764, 0.1189]],
dtype=torch.float16)
"""
int8_model = int8_model.to(0) # 양자화는 여기서 일어난다
print('After:', int8_model[0].weight)
"""
tensor([[ 3, -47, 54, ..., -5, -44, 47],
[-104, 40, 81, ..., 101, 61, 17],
[ -89, -127, -125, ..., 120, 19, -55],
...,
[ 82, 74, 65, ..., -49, -53, -109],
[ -21, -42, 68, ..., 13, 57, -12],
[ -4, 88, -1, ..., -43, -78, 121]],
device='cuda:0', dtype=torch.int8, requires_grad=True)
"""
restore_value = (int8_model[0].weight.CB * int8_model[0].weight.SCB) / 127
print('restore_value: ', restore_value)
"""
tensor([[ 0.0028, -0.0459, 0.0522, ..., -0.0049, -0.0428, 0.0462],
[-0.0960, 0.0391, 0.0782, ..., 0.0994, 0.0593, 0.0167],
[-0.0822, -0.1240, -0.1207, ..., 0.1181, 0.0185, -0.0541],
...,
[ 0.0757, 0.0723, 0.0628, ..., -0.0482, -0.0516, -0.1072],
[-0.0194, -0.0410, 0.0657, ..., 0.0128, 0.0554, -0.0118],
[-0.0037, 0.0859, -0.0010, ..., -0.0423, -0.0759, 0.1190]],
device='cuda:0')
"""==> FP16/BF16 -> Int8 -> FP16/BF16 으로 되돌리면 값에 일부 차이가 있다.
(모델 사용하기)
- 앞서 언급한 것 처럼 모델 입력은 FP16 이다. 모델 가중치는 Int8 이다
- int8_model은 nn.Sequential(Linear8bitLt(...),...) 이므로 bitsandbyts.nn.Int8Params 클래스의 모듈이다. torch의 nn.Parameter 클래스의 모듈이 아니다.
input_ = torch.randn((1, 64), dtype=torch.float16)
hidden_states = int8_model(input_.to(torch.device('cuda', 0)))
적용 관점(accelerate 사용)
- 큰 모델을 사용할때 accelerate 라이브러리를 유용한 유틸을 다수 제공합니다.
- accelerate의 init_empty_weights 메소드는 컨텍스트 매니저로 사용될 때 메모리(램)에 메모리를 전혀 사용하지 않습니다.
- 어떤 모델이든 init_empty_weights()로 초기화 되면, Pytorch' meta 디바이스에 적재되고, 메모리에 적재되지 않으며 shape와 dtype을 표현한다 (어떤 원리로??)
import torch.nn as nn
from accelerate import init_empty_weights
with init_empty_weights():
model = nn.Sequential([nn.Linear(100000, 100000) for _ in range(1000)]) # This will take ~0 RAM!
- 처음에 이 함수는 .from_pretrained 함수 내에서 호출되며 모든 매개변수를 torch.nn.Parameter로 오버라이드합니다. 위에서 설명한 대로 Linear8bitLt 모듈의 경우 Int8Params 클래스를 유지하려고 하므로 이는 우리의 요구 사항에 맞지 않습니다. 우리는 수정하는 다음 PR에서 이 문제를 해결했습니다.
# from
module._parameters[name] = nn.Parameter(
module._parameters[name].to(torch.device("meta"))
)
# to
param_cls = type(module._parameters[name])
kwargs = module._parameters[name].__dict__
module._parameters[name] = param_cls(
module._parameters[name].to(torch.device("meta")),
**kwargs
)
def replace_8bit_linear(model, threshold=6.0, module_to_not_convert="lm_head"):
for name, module in model.named_children():
if len(list(module.children())) > 0:
replace_8bit_linear(module, threshold, module_to_not_convert)
if isinstance(module, nn.Linear) and name != module_to_not_convert:
with init_empty_weights():
model._modules[name] = bnb.nn.Linear8bitLt(
module.in_features,
module.out_features,
module.bias is not None,
has_fp16_weights=False,
threshold=threshold,
)
return model- 이렇게 함으로써 nn.Linear 모듈을 bnb.nn.Linear8bitLt 로 변환할 수 있다??
- 위의 함수는 재귀 적으로 meta 디바이스의 nn.Linear 레이어를 Linear8bitLt 모듈로 변환한다.
- 위의 함수는 init_empty_weights 컨택스트 매니저 아래에서 수행됩니다.
: 해당 컨택스트 매니저 아래에서는 accelerate는 각 모듈의 파라미터를 수동적으로 로드하고, 적절한 장치로 이동시킵니다(??)
: bitsandbytes 에서 Linear8bitLt 모듈 장치를 세팅하는 것은 핵심적인 단계입니다(?)
: 양자화 단계는 두번 호출하면 안됩니다. 두번 호출하지 않기 위해 accelerate's set_module_tensor_to_device 함수(set_module_8bit_tensor_to_device)를 구현해야 했습니다.
요약하면 다음과 같다.
1. meta 디바이스에서 모델을 초기화 한다.
2. 파라미터를 적절한 GPU 상에서 하나하나 세팅하며, 이를 두번 수행하지 않도록 한다.
3. 새로운 키워드 인수를 모든 곳의 올바른 위치에 배치한다(??)
4. 광범위한 테스트를 추가한다.
(모든 내용을 옮겨온 것이 아니기 때문에 자세한 사항은 아래 참조 참고 부탁드립니다)
참조
A Gentle Introduction to 8-bit Matrix Multiplication for transformers at scale using transformers, accelerate and bitsandbytes
A Gentle Introduction to 8-bit Matrix Multiplication for transformers at scale using Hugging Face Transformers, Accelerate and bitsandbytes Introduction Language models are becoming larger all the time. At the time of this writing, PaLM has 540B parameters
huggingface.co
- bitsandbytes 이슈 삽질기 | Lablup Blog
bitsandbytes 이슈 삽질기 | Lablup Blog
바야흐로 LLM(Large Language Model, 대형 언어 모델)의 시대입니다. 2022년 11월, OpenAI가 발표한 ChatGPT는 AlphaGo의 자리를 이어받아 현대 인공지능의 대명사가 되었습니다. 많은 기업과 연구소에서는 ChatGP
blog.lablup.com
'최신 늬우스(News)' 카테고리의 다른 글
| SORA 톺아보기 (0) | 2024.04.25 |
|---|---|
| Claude3 모델 소개 (1) | 2024.03.24 |

