1. 개요
- NeRF는 2020년 NeRF: Representing Scenes as Neural Radiance Fields for View Synthesis라는 논문에 의해 소개되었다.
- 쉽게 말해 2D 이미지를 3D로 변환해 준다
- 엄밀하게는 여러장의 이미지를 입력 받아, 새로운 시점에서의 물체 이미지를 만들어내는 View Synthesis 모델이다.
- n개의 시점에서 불연속적인 2D 이미지를 입력 받아, 이미지가 연속적으로 구성될 수 있도록 임의 시점에서의 새로운 이미지를 만들어 낸다.

Nerf는 이미지 데이터에서 직접 학습하지만 CNN 레이어나 Transformer 레이어(적어도 원본은 사용하지 않음)를 사용하지 않는다. Nerf의 이점은 압축이다. 5–10MB에서 Nerf 모델의 가중치는 훈련에 사용되는 이미지 모음보다 작을 수 있다.
Nerf는 빛의 이동을 설명하는 light field or radiance field 개념을 사용한다. Light field는 빛의 이동을 5차원 Feature Space로 설명한다. Nerf 는 알려진 포즈가 있는 일련의 이미지(5차원 Feature Space)에서 (R,G,B, σ) 공간으로 매핑하는 함수를 근사화한다.
이는 이미지 앙상블에서 직접 3D Scene을 설명하는 'Generalized Scene Reconstruction' 기술의 한 방법이다.
2. 상세
- 입력: 물체의 위치 정보(x, y, z) 와 물체를 바라보는 방향(theta, phi)를 포함한 5차원 데이터를 입력으로 받는다
- 출력: RGB 값과 물체의 밀도(gamma)를 예측한다.
- 물체의 밀도는 투명도의 역수로, 값이 커지면 물체가 불투명해진다(뒤의 것이 잘 보이지 않음)

- 학습 과정: 총 9개의 FC와 Relu를 사용한다.
1) MLP로 학습
- 물체 위치 정보인 (x, y, z)만 8개 FC를 통과 시켜 물체의 밀도(Density)를 예측하고, 기존의 위치 정보(x, y, z)와 물체를
바라보는 방향값(theta, phi)를 합쳐서 9번째 FC를 통과 시켜 물체의 RGB를 예측한다
(1-1) 물체의 밀도는 바라보는 각도와 상관 없이 동일해야 하므로 처음 8개의 FC에서는 위치 정보만으로 학습하도록 하
였고
(1-2) 색(RGB)은 물체를 보는 방향에서 따라 달라지므로 물체는 보는 방향 값(theta, phi)을 마지막 FC에 입력으로 넣어
주었다.
- 이는 보는 각도에 따라 색이나 반사율이 다른 비 램버시안 효과(Non-Lambertian Effect) 때문이다
2) Volumn Rendering
- 저자들은 찍으려는 물체와 ray 위에 있는 모든 RGB 값을 weighted sum을 하였다.
- 한점의 밀도가 크면 그 점의 weight는 낮게 주고, 밀도가 작으면 그 점의 weight는 높게 주었다.
| ※ Ray 란 - Ray는 카메라 초점위치(o)에서 어떤 방향(d)로 t만큼 이동한 점들의 집합으로, 아래 이미지에서 빨간색, 파란색 선을 의미한다. - 하나의 Ray는 투영된 이미지에서 하나의 픽셀 값을 정한다.  - 카메라의 초점 위치(o)와 보는 방향(d)가 정해지면, 투영된 이미지 상에서 ray의 위치 좌표는 o+td를 통해 계산할 수 있다.  >>> 물체의 3차원 재구성은 Ray로 수행한다는 것을 알 수 있다. |
※ Weighted Sum 의 이해 1. A의 밀도 - A의 밀도가 높다면(투명도가 낮음) A는 선명하게 찍히고 밀도가 낮다면(투명도가 높음) A는 흐릿하게 찍힐 것이다. 2. B의 밀도 - B의 밀도(Density)가 높으면(투명도가 낮음) A가 잘 보이지 않을 것이고, B의 밀도가 낮으면(투명도가 높음) A는 잘 보일 것이다. |
| 위의 두 개념을 조합하면, Ray 위의 모든 점은 B와 같은 역할을 한다. 저자들은 피사체와 Ray 위의 모든 점의 RGB 값의 weighted Sum을 하였다. 한점의 밀도가 크면 그 점의 weight는 낮게 주고, 밀도가 작으면 그 점의 weight는 높게 주었다. |
3) 수식

r: ray. o+td
C(r): 이미지 픽셀의 RGB 값
t: 보고 있는 곳, weighted sum을 할 위치
t_n, t_f: ray가 물체를 통과할 때의 시작 점과 끝 점
T(t): transmittance, t보다 앞에 있는 점들의 밀도 합. 관측하는 물체 앞에 있는 점들의 밀도를 적분하고 – 부호를 주었.
– 부호는 값이 크면 관측하는 물체가 이 점들에 의해 가려진다는 의미를 보여준다.
σ(r(t)): t 지점에서의 밀도. 밀도가 클수록 선명해진다.
c(r(t), d): t 지점의 RGB 값. 실제 RGB의 weighted sum
이미지의 한 픽셀 값은 RGB 값과 밀도의 기댓값으로 계산할 수 있고, 여기에 transmittance 개념을 포함한다
4) Stratified sampling approach
- ray 상에는 무한한 점의 갯수가 존재하므로 n 등분하여 등분한 곳에서 모든 확률이 균일한 분포를 이루도록 점을 뽑는다.
- 이렇게 하면, Sampling 되는 점이 달라지므로 연속적인 값에 대해 학습이 가능하다.
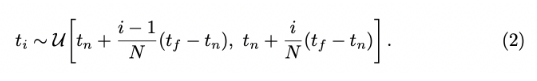
- 샘플링하여 불연속적인 점에 대해서는 Weighted Sum을 하면 (1) 식이 아래의 식으로 변하게 된다

5) Hierarchical volume sampling – Coarse network & Fine network
- ray 전체에서 sampling하여 학습을 하고(Coarse network), 학습된 결과에서 밀도 값이 크게 나온 부분만 골라 그 부분에서 다시 sampling하여 추가 학습을 합니다(Fine network)
- Nerf는 데이터 중 일부를 학습하여 새로운 시점에서 이미지를 생성(Inference)하고, 나머지 데이터(GT)와 비교를 한다. 생성한 이미지와 나머지 데이터 간의 로스를 비교하여 역전파를 수행한다.

6) Positional Encoding
- Nerf에서 Positional Encoding은 고주파 영역까지 학습할 수 있도록 하기 위함이다.
- 아래의 식을 통해 High Frequency 정보까지 잘 표현할 수 있다고 한다

- 식에서 L은 차원 수이고 3D 위치 정보에서는 L=10을 사용하여 차원을 60개로 늘려주고, 보는 방향에서는 L=4를 사용하여 차원을 24개로 늘려주었다.
3. 코드 분석
Nerf의 입력이 포지션(x,y,z)과 보는 방향(θ,φ)을 입력으로 받는다. 입력을 얻기 위해 역랜더링을 수행해야 한다. 정확하게는 샘플을 그릴 수 있는 각 픽셀과 각 픽셀에 대해 투영 라인을 그린다.
3D 공간에서 포인트를 샘플링하기 위해, 4x4 포즈 행렬에서 원점과 방향 벡터를 분리해 낸다.
포즈 행렬(전체 106개)
[[-9.9990219e-01 4.1922452e-03 -1.3345719e-02 -5.3798322e-02]
[-1.3988681e-02 -2.9965907e-01 9.5394367e-01 3.8454704e+00]
[-4.6566129e-10 9.5403719e-01 2.9968831e-01 1.2080823e+00]
[ 0.0000000e+00 0.0000000e+00 0.0000000e+00 1.0000000e+00]]
방향(전체 106개)
dirs = np.stack([np.sum([0, 0, -1] * pose[:3, :3], axis=-1) for pose in poses]) # (106, 3)
[ 0.01334572 -0.95394367 -0.29968831] # (101 index)
원점(전체 106개)
origins = poses[:, :3, -1] # (106, 3)
[-0.05379832 3.8454704 1.2080823 ] # (101 index)
3-1) 모든 이미지에 대해 월드 좌표계 기준으로 픽셀 방향(Ray Direction)과 원점(Ray Origin)을 구한다.
카메라 포즈를 이용해 각 픽셀에 대한 투영 선을 찾을 수 있다. 각 선은 원점과 방향으로 정의될 수 있다. 픽셀의 원점은 모두 동일하며 방향은 조금씩 다르다.
임의의 이미지와 포즈를 가져와서, 모든 픽셀에 대해 중심(origin)과 방향(direction)을 카메라 중심을 기준으로 구한다.
i, j = torch.meshgrid(
torch.arange(width, dtype=torch.float32).to(c2w),
torch.arange(height, dtype=torch.float32).to(c2w),
indexing='ij')
i, j = i.transpose(-1, -2), j.transpose(-1, -2)
directions = torch.stack([(i - width * .5) / focal_length,
-(j - height * .5) / focal_length,
-torch.ones_like(i)
], dim=-1)
# Apply camera pose to directions
rays_d = torch.sum(directions[..., None, :] * c2w[:3, :3], dim=-1)directions은 Principle Point를 중심으로 각 픽셀의 위치 좌표이며, 여기에 카메라 포즈를 곱해 [K|R]
각 픽셀이 월드 자표계 기준으로 정한 방향이 되게 한다 (rays_d) (shape: [100, 100, 3])
각 픽셀의 원점은 카메라 원점이 된다(rays_o) (shape: [100, 100, 3]) (동일한 값(3,)을 (100, 100)으로 늘려준다)
print(directions[..., None, :].shape) # [100, 100, 1, 3]
print(testpose[:3, :3].shape) # [3, 3]
print((directions[..., None, :] * testpose[:3, :3]).shape) # [100, 100, 3, 3]
print(torch.sum(directions[..., None, :] * testpose[:3, :3], dim=-1).shape) # [100, 100, 3]>>> 카메라 좌표계 기준 각 픽셀 방향(directions)에 카메라 포즈(testpose)를 곱하기 위해 위와 같이 연산을 취하는데
조금더 봐야 이해가 갈 것 같다.
Ray Origin
torch.Size([100, 100, 3])
tensor([-1.9745, -1.8789, 2.9700], device='cuda:0')
Ray Direction
torch.Size([100, 100, 3])
tensor([ 0.4898, 0.4661, -0.7368], device='cuda:0')
rays_o = ray_origin.view([-1, 3]) #shape: [10000, 3]
rays_d = ray_direction.view([-1, 3]) #shape: [10000, 3]
3-2) 이미지 모든 픽셀에 대해 n_samples된 위치를 구한다
Ray를 n 등분하여 등분한 곳에서 모든 확률이 균일한 분포를 이루도록 점을 뽑는다
near ~ far 지점에 n_samples 갯수 만큼 랜덤하게 균일 분포로 점을 샘플링한다.
한 이미지당 점들의 Shape는 (100, 100, n_samples, 3)가 된다. 간단하게 (10000, n_samples, 3)이 된다.

3-3) 포지셔널 인코딩, 고주파 학습을 용이하게 한다
모델이 고주파 변화를 학습하는데 도움이 되도록, 고주파 함수를 사용하여 연속 입력을 고차원 공간에 매핑한다.
보는 지점과 시선 방향에 대해 Encoder를 생성한다.
encoder = PositionalEncoder(3, 10) # len(self.embed_fns) : 21
viewdirs_encoder = PositionalEncoder(3, 4) # len(self.embed_fns) : 9
# Grab flattened points and view directions
pts_flattened = pts.reshape(-1, 3) # [80000, 3]
viewdirs = rays_d / torch.norm(rays_d, dim=-1, keepdim=True) # [10000, 3] 정규화 한다?
flattened_viewdirs = viewdirs[:, None, ...].expand(pts.shape).reshape((-1, 3))
# 모든 점에 대해서 viewdirs를 생성하고 [80000, 3]
# # Encode inputs
encoded_points = encoder(pts_flattened) # torch.Size([10000, 3])
encoded_viewdirs = viewdirs_encoder(flattened_viewdirs)
print('Encoded Points')
print(encoded_points.shape) # [80000, 63]
print(torch.min(encoded_points), torch.max(encoded_points), torch.mean(encoded_points))
print('')
print('Encoded Viewdirs')
print(encoded_viewdirs.shape) # [80000,, 27]
print(torch.min(encoded_viewdirs), torch.max(encoded_viewdirs), torch.mean(encoded_viewdirs))
print('')
>>>
Encoded Points
torch.Size([80000, 63])
tensor(-2.8518, device='cuda:0') tensor(3.5515, device='cuda:0') tensor(0.0250, device='cuda:0')
Encoded Viewdirs
torch.Size([80000, 27])
tensor(-1., device='cuda:0') tensor(1., device='cuda:0') tensor(0.1056, device='cuda:0')결론적으로 점은 [80000, 3] --> [80000, 63] 이 된 것이고
바라보는 방향은 [10000, 3] --> [80000, 3] --> [80000, 21] 이 된 것인데
위의 연산 처럼 하면 고주파에 대해서 더 잘 학습하는 지는 공부가 더 필요한 것 같다.
3-4) Nerf 구조
- 원본 논문은 Radiance Field 함수를 MLP로 구현하였지만, MLP가 꼭 아니더라도 다른 근사 함수를 사용할 수 있다. 예를 들어, Plenoxels(Yu et al) 논문은 Basis of Spherical Harmonics 를 사용하였고, 빠르고 경쟁적인 결과를 내었다.
- Nerf 모델은 대부분 레이어에서 256 차원을 가지는 깊이 8 네트워크이며, Residual 연결은 레이어 4에 배치된다.
- 이 레이어 후에 RGB 와σ(밀도) 가 생성된다. RGB 값은 선형 레이어로 추가 처리된 다음 뷰 방향과 연결되고, 또 다른 선형 레이어를 통과한 다름 최종적으로 출력에서 σ(밀도)와 재결합 된다.

3-5) Volume Rendering
- 각 픽셀의 광선을 따라 모든 샘플의 가중치 합계를 취하여 예상 색상 값을 얻는다.
- 각 RGB 샘픔은 Alpha 값으로 가중치가 부여된다. Alpha 값이 높을 수록 샘플링 된 영역이 불투명할(opaque) 가능성이 높으므로 멀리 있는 지점이 가려질 가능성이 높다.
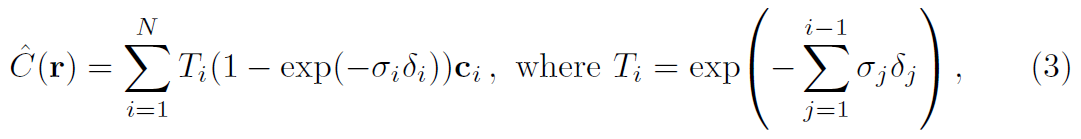
tf.math.cumprod(x, exclusize=True) 와 아래 연산이 동일해서 Torch는 아래 3단계로 연산하였다.
# Compute regular cumprod first (this is equivalent to `tf.math.cumprod(..., exclusive=False)`).
cumprod = torch.cumprod(tensor, -1)
# "Roll" the elements along dimension 'dim' by 1 element.
cumprod = torch.roll(cumprod, 1, -1)
# Replace the first element by "1" as this is what tf.cumprod(..., exclusive=True) does.
cumprod[..., 0] = 1.
3-6) Hierarchical Volume Sampling
Nerf 아키텍쳐
1. 각 픽셀에 대해 장면을 통해 카메라 광선을 따라가며 (x, y, z, d) 위치에서 샘플 세트를 수집한다.
2. 출력값(r, g, b, σ)를 생성하기 위한 입력으로 각 샘플에서 (x, y, z, d) 점과 보는 방향을 사용한다.
3. 고전적인 볼륨 랜더링 기술을 사용하여 이미지를 구성한다.
Plenoxels 논문에서는 NN을 사용하지 않고, '구형 Harmonics의 기저'를 사용하였다(?)
Differentiable Volume Renderer
각 RGB 샘플은 Alpha 값으로 가중치가 부여된다. 알파값이 높을 수록 샘플링 된 영역이 불투명할(opaque) 가능성이 높으므로, 멀리있는 점에 가려질 가능성이 있다(?)
Stratified Sampling
- 계층적 샘플링
- Nerf 모델에서 카메라가 궁극적으로 포착하는 RGB 값은 이미지 픽셀을 통과하는 광성을 따라 축적된 빛 샘플이다.
- 고전적인 Volume Rendering 접근법은 Ray를 따라 포인트를 누적한 다음 통합하여 각 포인트에서 광선이 입자에 부딫히지 않고 이동할 확률을 추정한다.
- 따라서, 각 픽셀에는 픽셀을 통과하는 광선을 따라 포인트 샘플링이 필요하다. 최적의 적분 값을 근사하기 위해서, 계층적 샘플링 접근 방식은 공간을 N개의 BINS로 나누고 각 BIN에서 균일하게 샘플을 추출한다.
- 계층적 샘플링 방식을 사용하면 네트워크가 연속공간에서 학습하도록 유도할 수 있다

Hierarchical Volume Sampling
- 계층적 볼륨 샘플링
- Radiance Field는 정확하게는 2개의 MLP로 표현되는데 하나는 대략적인(Coarse) 수준에서 작동하여 장면의 광범위한 구조적 속성을 인코딩하고, 다른 하나는 미세(fine) 수준에서 세부 사항을 다듬어 메쉬 및 가지와 같은 얇고 복잡한 구조를 실현할 수 있다
- 또한, 2개의 MLP는 각각이 받는 샘플이 다르며 대략적인(Coarse) 모델은 광선 전체에서 광범위하고 대부분 규칙적인 간격의 샘플을 처리하고, 미세(fine) 모델은 두드러진 정보에 사전 확률(Prior)가 강한 영역에 집중한다.

- 실제로 3D 공간은 폐색(Occlusion)으로 부터 희박하므로 대부분의 포인터는 랜더링된 이미지에 크게 기여하지 못한다. 그러므로, 적분에 기여할 가능성이 높은 영역을 오버샘플링 하는 것이 유리하다.
- 첫번째 샘플 집합에서 학습되고 정규화된 가중치를 적용하여, 광선 전체에서 확률밀도함수(PDF)를 계산한다. 그다음 이 확률밀도함수에 역변환 샘플링을 적용하여 두번째 샘플 집합을 수집한다. 이 집합은 첫번째 집합과 결합되어 미세(fine) 네트워크에 공급되어 최종 출력을 생성한다.
| ※ 몬테카를로(Monte Carlo) 방법이란? - 몬테카를로 방법이란 난수를 이용하여 함수의 값을 확률적으로 계산하는 알고리즘을 부르는 용어이다. - 즉, 수치적인 샘플링 기법을 통한 확률 모델의 근사 방법을 말한다. |
Inverse CDF Method
- Inverse CDF Method(역 누적 분호 함수)는 모든 확률 분포의 누적 분포 함수(cdf)가 균등분포(Uniform Distribusion)을 따른다는 성질을 이용한 방법이다.
(1) 기본 난수 생성기(Basic Random number generator)
: 기본적인 난수 생성기는 균등분포로 0~1사이 값을 생성한다
: 모든 프로그램은 난수 생성기를 기본 함수로 가지고 있다
: 균등분포 난수 생성기가 없다면, 다른 분포를 가지는 난수 생성기는 만들 수 없다.
: 균등분포 난수 생성기만 있으면, 어떤 분포를 가지는 난수 생성기는 만들 수 있다.
(2) 균등 분포의 보편성
: 모든 확률 변수의 누적분포함수(CDF, F(X))는 균등분포를 따른다.
: 기본 난수 생성기(균등분포)의 난수 생성 범위는 0~1사이이다

: 만약 확률변수 X의 누적분포함수(CDF)인 F(x)의 역함수를 계산할 수 있다면, 아래 식과 같이 기본 난수 생성기인 균등 분포를 이용해서 확률 변수 X에 대한 샘플링이 가능해 진다.



정규분포 누적분포함수의 역함수는 위의 그림과 같이 쌍곡선 함수 형상을 띔을 확인할 수 있다.
ex)
(1) 정규분포의 확률밀도함수(PDF)를 이용해서 누적분포함수(CDF)를 구한다.
(2) 누적분포함수의 역함수를 구한다(누적분포함수 U를 두고, x에 대해 정리한다)
(3) 균일분포 샘플을 역함수에 통과시킨다.
참고 자료)
NeRF: 2D 이미지를 3D로 바꿔준다고요?
요즘 인공지능 분야에서 핫한 분야가 무엇일까요? 아마도 NERF가 아닐까 싶습니다. NeRF(Neural radiance Fields)는 2D 이미지를 3D로 변환해주는 모델입니다. 이번 콘텐츠에서는 NeRF에 대해 알아보겠습니
modulabs.co.kr
추가 참고 문헌)
- https://towardsdatascience.com/its-nerf-from-nothing-build-a-vanilla-nerf-with-pytorch-7846e4c45666
It’s NeRF From Nothing: Build A Vanilla NeRF with PyTorch
A tutorial for how to build your own NeRF model in PyTorch, with step-by-step explanations of each component.
towardsdatascience.com
- https://blog.naver.com/PostView.nhn?blogId=jinis_stat&logNo=221648391742
Sampling 방법 / Inverse CDF Method
Sampling Methods 앞으로 monte carlo 섹션에서의 포스팅에서는, 샘플링 방법(Sampling Method)에 대해...
blog.naver.com
- https://ratsgo.github.io/statistics/2017/06/27/normal/
정규분포 누적분포함수와 중심극한정리 · ratsgo's blog
이번 글에서는 정규분포(Normal Distribution)과 중심극한정리(Central Limit Theorem)을 간단한 파이썬 코드 중심으로 살펴보도록 하겠습니다. 이 글은 ‘밑바닥부터 시작하는 데이터과학(조엘 그루스, 인
ratsgo.github.io
[1] Ben Mildenhall, Pratul P. Srinivasan, Matthew Tancik, Jonathan T. Barron, Ravi Ramamoorthi, Ren Ng — NeRF: Representing Scenes as Neural Radiance Fields for View Synthesis (2020), ECCV 2020