출처)
https://www.countbayesie.com/blog/2017/5/9/kullback-leibler-divergence-explained
Kullback-Leibler Divergence Explained — Count Bayesie
Kullback–Leibler divergence is a very useful way to measure the difference between two probability distributions. In this post we'll go over a simple example to help you better grasp this interesting tool from information theory.
www.countbayesie.com
(번역)
해당 포스트에서는 '두개의 확률분포'를 KL Divergence(Kullback Leibler Divergence)라는 방법을 이용해서 비교를 진행 해본다.
우리는 종종 관찰된 데이터(혹은 복잡한 데이터 분포)를 간단한(혹은 근사하는) 확률/통계 모델로 나타내곤 한다.
KL Divergence는 이러한 근사 모델이 얼마나 정보를 잃어버렸는지 측정하는데 도움을 준다.
역자 Comment)
확률/통계 모델은 데이터를 대략적으로 표현해주는 방법이니 정보의 손실이 있을 수 밖에 없다. 다만, 정보를 최대한 안 잃어 버리는 모델은 선택할 수 있다.
우리가 외계행성을 방문하여 10개의 이빨을 가진 벌레를 만났고, 이빨 갯수를 관찰해 본다고 해보자. 몇몇 벌레는 이빨 사용으로 인해 몇몇 이빨을 잃었고, 따라서, 충분한 샘플링 후에 우리가 아래와 같은 분포 관찰했다고 해보자.

하지만, 위의 수집 정보를 지구로 전송한다고 했을 때 데이터가 너무 크다면, 분포를 나타낼 수 있는 다른 확률 모델이 필요할 것이다.
균등 분포 모델로 나타내 보자. 11개의 가능한 경우가 있고, 우리는 모든 가능성에 대해 1/11의 확률을 할당할 수 있다.
따라서, 아래와 같이 분포로 나타낼 수 있다. 하지만, 이는 우리가 수집한 데이터 분포와는 확실히 다르다.
역자 Comment)
본인은 위의 두 문장을 이해하지 못했다. 왜 균등 분포로 나타내면 아래와 같은 분포를 나타내는지.

만약 이항 분포로 표현한다고 해보자. 우리가 해야할 것은 확률 파라미터 P를 측정하는 것이다. 만약 우리가 n번의 시행을 하고 확률이 p라면 기대 값은 다음과 같다. $ E[x] = n \cdot p $.
이때 n=10이고 E[x]는 평균 값인 5.7이라 하면, p는 0.57이 된다. 따라서, 아래와 같은 이항분포를 갖게 된다.

역자 Comment)
여기서 이항 분포로 나타낸다고 하면 왜 n = 10이 되는지는 본인은 이해하지 못했다.
위에서 구한 각각의 모델을 비교해 보면, 어떠한 모델도 본래 데이터 관찰로 얻어진 확률 모델과 유사하지 않다는 것을 알 수 있다. 우리는 두개 대안의 확률 모델(균일 분포, 이항분포)로서 정보를 표현할 때 단지 두개의 파라미터(n, p)로만 나타낼 수 있는 이점이 있지만, 잃는 것도 있었다. 여기서 얼마나 정보를 잃었는지 측량할 수 있을까? 여기서 Kullback Leibler Divergence 개념이 등장한다.

확률 분포의 엔트로피
KL Divergence 개념은 정보 이론에서 유래하였고, 정보 이론의 가장 큰 목적은 데이터 상에 얼마만의 정보가 있는지 측량하는 개념이다. 측량 메트릭은 '엔트로피(H)'라 불린다. 확률 분포의 엔트로피는 아래와 같이 나타낸다.
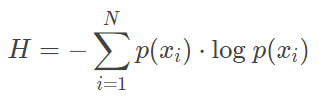
만약 식에서 $log_2$를 사용한다면 우리는 엔트로피 식을 "정보를 암호화(Encode)하기 위한 최소한의 비트수"로 해석할 수 있다. 위의 식에 우리가 풀고자 하는 문제의 경험적 확률 분포(행성에서 얻은 데이터 분포)를 대입해 보면 3.12bit를 갖게 된다. 이 비트는 우리가 수집된 데이터의 각 관찰을 표현하기 위한 최소한의 평균 비트수를 나타낸다고 할 수 있다.
엔트로피는 정보를 최적화하여 암호화(Encode)하는 방법은 알려주지 않는다. 다만, 최소한의 필요한 비트수를 앎으로서 우리는 수집한 데이터에 얼마만의 정보가 있으며, 이를 표현하는 각 확률 분포가 얼마만의 정보를 손실하는지 확인해 볼 수 있다.
KL Divegence로 잃어버린 정보 량 측정
엔트로피 식과는 조금 다르다. 근사 분포 q를 추가한다.
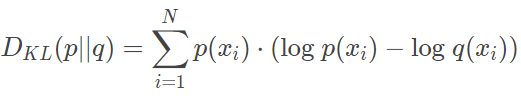
궁극적으로 구하고자 하는 것은 원본 데이터 확률 분포와 근사 분포와의 로그 차이 값의 기대값이다. 식을 아래와 같이 다시 쓸 수 있다.
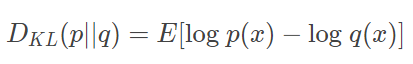
다시 예시로 돌아와서
우리는 이항 분포로 데이터 분포를 표현한 것이 더 많은 정보 손실이 있음을 확인할 수 있다.

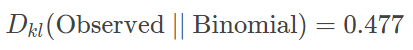
KL Divergence 메트릭은 대칭이 아니기 때문에 관점을 바꾸면(이항 분포에 근사하기 위해 수집된 데이터 확률 분포를 이용하면) 전혀 다른 결과를 얻는다.

(중간 부분 생략...)
KL Divergence를 잘 활용하면, 신경망의 목적 함수(Cost Function)로 사용하여 데이터를 설명하는 모델의 최적 값을 찾을 수 있다. 고차원의 다수 파라미터를 가지는 모델로도 확장할 수 있다.
KL Divergence와 Neural Network를 이용하면 매우 복잡한 근사 확률 분포도 학습 시킬 수 있다. 일반적으로 이러한 접근법을 "Variational Autoencoder"라고 한다.
Variational Autoencoder 방법을 포함한 Variational Bayesian 방법은 KL Divergence를 사용하여 최적의 근사 분포를 생성하므로 효율적인 추론이 가능하다.
역자 결론)
| - KL Divergence는 데이터를 표현한 확률 모델이 정보 손실이 얼마나 있었는지를 측정하는 메트릭이다. - 엔트로피를 사용하며, 신경망 학습의 목적함수로 사용되어 효율적인 최적화를 가능하게 하는데도 쓰인다. 이를 'Variational Autoencoder' 방법으로 부르기도 한다. |
[참고]
https://arxiv.org/abs/1606.05908
Tutorial on Variational Autoencoders
In just three years, Variational Autoencoders (VAEs) have emerged as one of the most popular approaches to unsupervised learning of complicated distributions. VAEs are appealing because they are built on top of standard function approximators (neural netwo
arxiv.org
'데이터 과학 > 데이터 과학' 카테고리의 다른 글
| np.percentile 사용법 (2) | 2023.01.17 |
|---|---|
| Json 파일 읽어 들이는 2가지 방법 (0) | 2022.01.20 |
| Density Estimation (in Python) (0) | 2021.03.26 |
| [MIT] 데이터 사이언스 기초 강의 요약[11 ~ 15강] (0) | 2020.11.29 |
| JSON (JavaScript Object Notation) in C (0) | 2020.11.09 |

