소개
- 코드 라마는 라마 2를 기반으로 한 코드 전용 대규모 언어 모델로, 오픈 모델 중 최고의 성능을 제공하며, 큰 입력 컨텍스트 지원, 프로그래밍 작업을 위한 제로샷 명령 수행 능력 등을 갖추고 있습니다.
- 다양한 응용 프로그램을 커버하기 위해 여러 가지 버전을 제공합니다
: 파운데이션 모델(코드 라마), 파이썬 전문화(코드 라마 - 파이썬), 명령 수행 모델(코드 라마 - 인스트럭트) 각각 7B, 13B, 34B 파라미터를 가집니다.
- 모든 모델은 16k 토큰 시퀀스에 대해 훈련되었으며, 최대 100k 토큰까지 입력에서 개선을 보여줍니다.
- 코드 라마는 라마 2를 더 많은 샘플링 코드를 사용하여 세부 조정하여 개발되었습니다.
다운로드 및 모델 사이즈
- llama2와 동일한 경로에서 모델 접근 허가를 받는다. URL을 발송해준다.
git clone https://github.com/facebookresearch/codellama.git
cd codellama
bash download.sh # 이후 전달 받은 URL을 입력한다.
...
Enter the list of models to download without spaces
(7b,13b,34b,70b,
7b-Python,13b-Python,34b-Python,70b-Python,
7b-Instruct,13b-Instruct,34b-Instruct,70b-Instruct), or press Enter for all
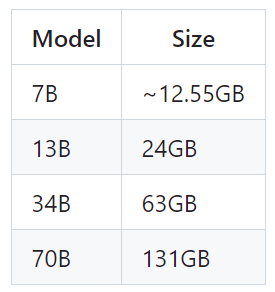
- 70B 파이썬 및 인스트럭트 버전을 제외한 모든 모델은 최대 100,000 토큰의 시퀀스 길이를 지원하지만,
- 최대 시퀀스 길이(max_seq_len)와 최대 배치 크기(max_batch_size) 값에 따라 캐시를 사전 할당합니다. 따라서 하드웨어와 사용 사례에 맞게 이들 값을 설정하세요.
사전 훈련된 코드 모델
- 코드 라마와 코드 라마 - 파이썬 모델은 지시 사항을 따르도록 세부 조정되지 않았습니다.
- 예상되는 답변이 프롬프트의 자연스러운 연속이 되도록 프롬프트해야 합니다.
예시를 보려면 example_completion.py를 참조하세요. 예를 들어, CodeLlama-7b 모델로 실행하는 명령은 아래와 같습니다(노드 당 프로세스 수(nproc_per_node)는 MP 값으로 설정해야 합니다):
torchrun --nproc_per_node 1 example_completion.py
--ckpt_dir CodeLlama-7b/
--tokenizer_path CodeLlama-7b/tokenizer.model
--max_seq_len 128 --max_batch_size 4
사전 훈련된 코드 모델은 다음과 같습니다:
코드 라마 모델: CodeLlama-7b, CodeLlama-13b, CodeLlama-34b, CodeLlama-70b
코드 라마 - 파이썬 모델 CodeLlama-7b-Python, CodeLlama-13b-Python, CodeLlama-34b-Python, CodeLlama-70b-Python.
코드 채우기 기능(Code Infilling)
-코드 라마와 코드 라마 - 인스트럭트 7B 및 13B 모델은 주변 컨텍스트가 주어진 상황에서 코드를 채워넣을 수 있습니다.
예제를 보려면 example_infilling.py를 참조하세요.
CodeLlama-7b 모델은 아래 명령으로 인필링을 실행할 수 있습니다(노드 당 프로세스 수(nproc_per_node)는 MP 값으로 설정해야 합니다):
torchrun --nproc_per_node 1 example_infilling.py
--ckpt_dir CodeLlama-7b/
--tokenizer_path CodeLlama-7b/tokenizer.model
--max_seq_len 192 --max_batch_size 4
사전 훈련된 인필링 모델은
코드 라마 모델 CodeLlama-7b와 CodeLlama-13b
코드 라마 - 인스트럭트 모델 CodeLlama-7b-Instruct, CodeLlama-13b-Instruct입니다.
세부 조정된 지시 모델
- 코드 라마 - 인스트럭트 모델은 지시사항을 따르도록 세부 조정되었습니다.
- 7B, 13B, 34B 변형의 기대되는 기능과 성능을 얻기 위해서는 chat_completion()에 정의된 특정 형식을 따라야 합니다.
- 이에는 INST 및 <<SYS>> 태그, BOS 및 EOS 토큰, 그리고 공백 및 줄바꿈이 포함되어 있습니다
(더블 스페이스를 피하기 위해 입력값에 strip()을 호출하는 것이 좋습니다).
- CodeLlama-70b-Instruct는 dialog_prompt_tokens()에 정의된 별도의 회전 기반(?) 프롬프트 형식을 요구합니다.
- 모든 인스트럭트 모델로 답변을 생성하기 위해 chat_completion()을 직접 사용할 수 있으며, 필요한 형식을 자동으로 수행합니다.
- 추가적으로, 안전하지 않다고 판단되는 입력과 출력을 필터링하기 위한 분류기를 배포할 수도 있습니다. 입력과 출력의 추론 코드에 안전 검사기를 추가하는 방법의 예는 llama-recipes 저장소에서 확인할 수 있습니다.
torchrun --nproc_per_node 1 example_instructions.py \
--ckpt_dir CodeLlama-7b-Instruct/ \
--tokenizer_path CodeLlama-7b-Instruct/tokenizer.model \
--max_seq_len 512 --max_batch_size 4
세부 조정된 지시 사항을 따르는 모델은
코드 라마 - 인스트럭트 모델 CodeLlama-7b-Instruct, CodeLlama-13b-Instruct, CodeLlama-34b-Instruct, CodeLlama-70b-Instruct입니다.
코드 라마는 사용과 함께 잠재적 위험을 가진 새로운 기술입니다. 지금까지 실시된 테스트는 모든 시나리오를 커버하지 못했으며 커버할 수도 없습니다. 개발자들이 이러한 위험을 해결할 수 있도록 돕기 위해, 우리는 책임 있는 사용 가이드를 만들었습니다. 더 자세한 내용은 우리의 연구 논문에서도 찾아볼 수 있습니다.

Llama-recipes/ Getting_to_know_Llama.ipynb 톱아보기
<목차>
- Chatbot Architecture
- 1. Chat Conversation
- 2. Prompt Engineering
- 2.1. In-Context Learning (e.g. Zero-Shot, Few-Shot)
- 2.2 Chain of Thought
- 2.3.1. Langchain
- 2.3.2. Langchain Q&A Retriever
- Chatbot Architecture
: 핵심 컴포넌트
- User Prompts
- Input Safety
- Llama2
- Ouput Safety
- Memory & Context

1. Chat Conversation
- LLMs are stateless
- Single Turn
- Multi Turn (Memory)
2. Prompt Engineering
: 프롬프트 엔지니어링은 원하는 응답을 얻기 위해 효과적인 프롬프트를 설계하는 과학을 말합니다.
: 할루시네이션 감소
2.1. In-Context Learning (e.g. Zero-Shot, Few-Shot)
: 문맥 속 학습은 '테스크에 대한 데모'가 프롬프트의 일부로 제공되는 프롬프트 엔지니어링의 특정 방법이다.
- Zero-Shot 학습 - 모델이 입력 예제 없이 작업을 수행합니다.
- Few-Shot 또는 "N-Shot" 학습 - 모델이 사용자 프롬프트의 입력 예를 기반으로 수행되고 작동합니다.
2.2 Chain of Thought
: "사고의 사슬"은 논리적인 단계별 사고를 통해, 복잡한 추론을 가능하게 하고 의미 있고 상황에 맞는 반응을 생성한다.

2.3 Retrieval Augmented Generation (RAG)
- 프롬프트 엔지니어링은 지식과 전문 데이터가 부족한 한계가 있다.
- RAG는 외부 데이터 소스로 부터 정보 조각을 가져와 사용자 프롬프트를 증강 시켜 적절한 답변을 얻는 기법이다.
2.3.1. Langchain
2.3.2. Langchain Q&A Retriever
- RecursiveCharacterTextSplitter, FAISS, HugginFaceEmbedding
- langchain.chains.ConversationRetrievalChain
3. Fine-Tuning Models
- 프롬프트 엔지니어링과 RAG도 한계가 있을 때 파인튜닝을 고려해 볼 수 있다.
- Fine-Tuning Arch
- Types (PEFT, LoRA, QLoRA)
- Using PyTorch for Pre-Training & Fine-Tuning
- Evals + Quality

Llama 모델 관련 페이지는 아래 3곳이 존재한다.
meta-llama (Meta Llama 2) (huggingface.co)'
meta-llama (Meta Llama 2)
Llama 2 From Meta Welcome to the official Hugging Face organization for Llama 2 models from Meta! In order to access models here, please visit the Meta website and accept our license terms and acceptable use policy before requesting access to a model. Requ
huggingface.co

https://ai.meta.com/research/publications/code-llama-open-foundation-models-for-code/
Code Llama: Open Foundation Models for Code | Research - AI at Meta
Abstract We release Code Llama, a family of large language models for code based on Llama 2 providing state-of-the-art performance among open models, infilling capabilities, support for large input contexts, and zero-shot instruction following ability for
ai.meta.com
Introducing Code Llama, a state-of-the-art large language model for coding (meta.com)
Introducing Code Llama, a state-of-the-art large language model for coding
Code Llama is a code-specialized version of Llama 2 that was created by further training Llama 2 on its code-specific datasets, sampling more data from that same dataset for longer. Essentially, Code Llama features enhanced coding capabilities, built on to
ai.meta.com
참고) Llama 2에 세계가 열광하는 이유는? (메타 라마2 개념/특징/사용법까지) - 모두레터 (modulabs.co.kr)
'LLM > Llama' 카테고리의 다른 글
| GGUF 파일이란? (0) | 2024.05.06 |
|---|---|
| [Llama-recipes] Readme.md 톺아보기 (0) | 2024.03.11 |
| [Llama-recipes] LLM_finetuning (0) | 2024.03.04 |
| Code Llama FineTune (0) | 2024.02.19 |



