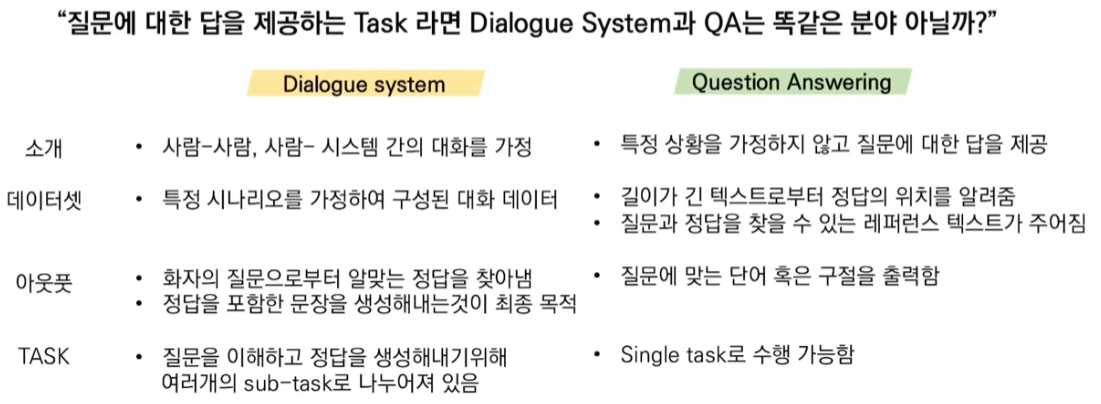
1. Task-Oriented Dialog system
- 특정 Task에서 사용자 요구사항 파악하고 이를 해결하기 위한 대화 시스템
- 특정 시나리오를 가정하여 구성된 대화 데이터
2. ToD 종류
- Single Turn 대화
- Multi Turn 대화
3. FAQ와의 차이점
- FAQ는 TOD 대비 질문-정답 쌍이 사전에 존재, 질문에 맞는 구절을 출력한다.
- TOD는 질문을 이해하고, 정답을 포함한 문장을 생성하는 것이 목적
: 사용자 의도를 파악하기 위한 여러 Sub-Task가 존재할 수 있음
4. ToD 구성
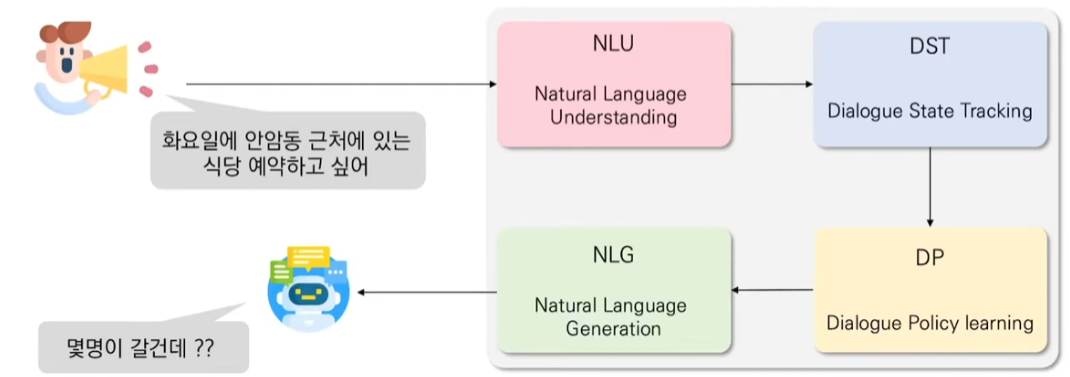
대략 4개의 모듈로 이뤄짐. 각각이 독립 모델이지만, 입/출력이 순차적임.
NLU
- 사용자 대화를 이해
- Utterance(발화)와 Semantic Frame(Speech-act, intent, slot)을 매핑
e.g.
Utterance(발화) : "4 명이 갈거야"
Slot: ↑B-People O O O O
Domain: Restaurant
Intent: Restaurant_Book
--> 발화를 Speech-act(?), intent, slot과 매핑
DST
- Partial Dialogues를 Dialogue 상태에 매핑시키는 Dialogue-Level Task
- 입력: Dialogue + previous state(이전 상태)
- 출력: Dialogue State (Slot-Value pairs)

DP
- DST로 부터 추출된 Dialogue State를 기반으로 시스템 액션을 결정함
- 입력: Current Dialogue State + Knowledge Base Results(외부 지식이 필요하다)
- 출력: 시스템 액션(Speech-act + Slot-Value pairs)

--> 외부 지식은 여기선 안암동 근처 2인이 예약가능한 OO 식당을 의미한다.
NLG
- 시스템 액션을 자연어 응답으로 변환
- 입력: Speech-act + Slot-Value(option)
- 출력: 자연어 응답

-->
DP에서 시스템 액션이 OO 식당을 알려주는 역할만 하나? 그렇다면 KB와 차이가 없을 것.
OO 식당을 예약하는 에이전트 역할을 해야 할 것.
NLG는 "OO 식당을 예약했습니다" 응답을 내야 할 것.
5. DST 상세
- dst는 Domain과 (Slot, Value)를 찾아가는 과정
- 주요 방법
1) Predefined Ontology
2) Open Vocabulary



-->
어려운 점은 예상 가능한 대화의 도메인과 Slot, Value를 미리 정의하는 건(Ontology 방식) 경우의 수가 너무 많기 때문에 Open Vocabulary 상황에서도 좋은 성능을 달성할 수 있느냐 하는 것
대화가 다수의 도메인을 포함할 수 있기 때문에 다수의 도메인에서도 Slot-Value를 잘 추출하고 트레킹 할 수 있는지가 관건
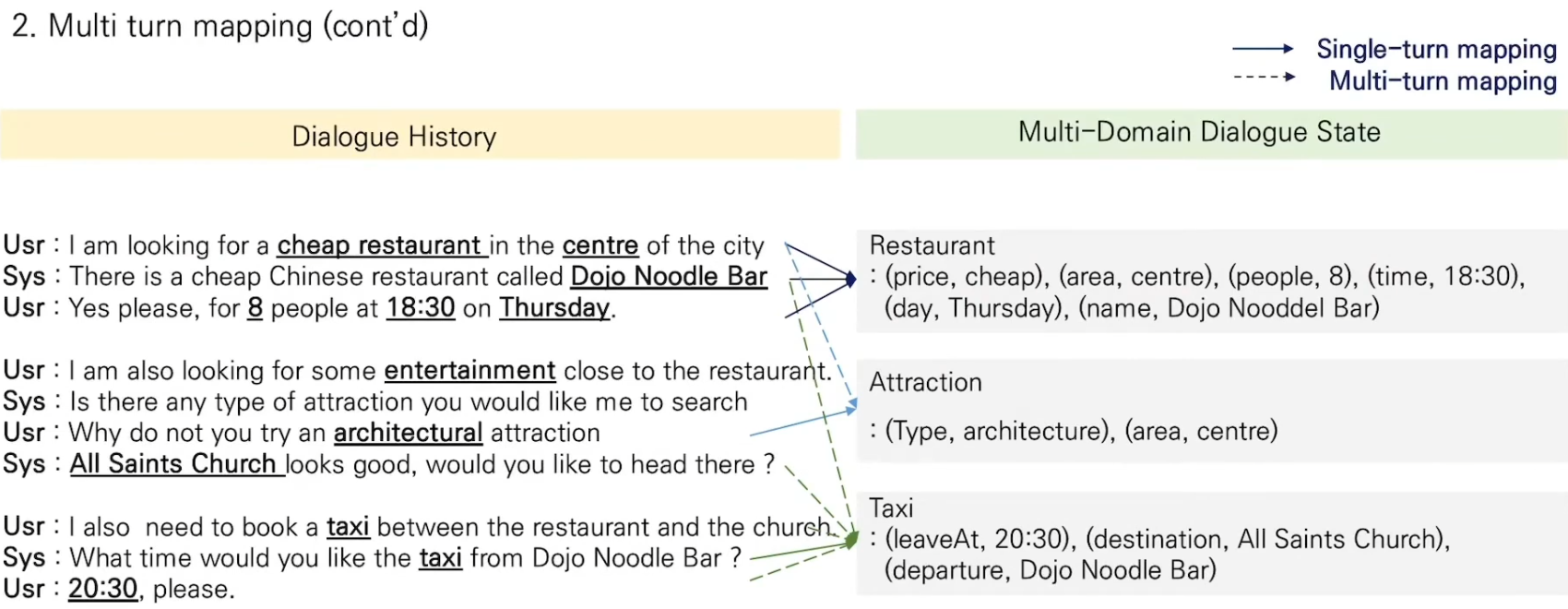
6. TRADE 모델
- 멀티 도메인 데이터셋에서 성능을 높이기 위해 Domain간 Tracking된 정보를 공유
- 여러 도메인의 데이터를 하나의 모델로 학습(=parameter sharing)
(논문 내용은 생략)
사전 정의(1)

사전 정의(2)

추가 참고)
[Paper Review] Structure Extraction in Task-Oriented Dialogues with Slot Clustering (youtube.com)
[Paper Review] Slot Self-Attentive Dialogue State Tracking (youtube.com)
안 중요한 참조들)
- GitHub - windszzlang/DiagGPT: Code and data repo for "DiagGPT"
